
I got pretty good in Mandarin within 12 months of rigorous part-time study. I'm not even close to perfectly fluent, but I got far into intermediate fluency. Read my personal story of learning Mandarin here: isaak.net/mandarin
This post on my Methods of Mandarin (MoM) is for fellow language learners and autodidacts. This isn't a thorough how-to guide. I won't be holding your hand. It's more like a personal notebook of what worked for me. I'm sharing my personal Anki deck and then I'll describe all my methods and tips. People's styles and methods differ.
Bookmark the post, skip through it as needed, return to it. I recommend using the table of contents to navigate. It fully expands as a convenient sidebar on a fullscreen desktop.
Structure of this post: Anki → Beginner → Intermediate → Advanced.
Spaced Repetition
My most important method of learning Chinese is Anki.
The heart of my language learning is spaced repetition. It's absurdly overpowered. Here's Gwern's review of the literature on how effective SRS is.
There’s many spaced repetition apps. I like Anki. Anki has the most active community, the most add-ons regular updates, and, most importantly, the most pre-made decks. Generally, I use Anki for quite a lot of different things:





Anki is great, and in the toolkit of many top-tier students, especially in memorization-heavy fields (medicine!). It’s great for not forgetting already learned things.
During learning Chinese, I'd spend as much as two hours on Anki a day, and while travelling China up to four hours. When not actively studying a new field or language, I try to keep up a little Anki habit of around 30 min a day. It's easy to do in between things, like on the toilet or in public transit. It’s important to stay consistent, but I don’t worry if I have to take a few week’s break.
It's important to remember that too much Anki becomes a distraction. The most important piece is actually going out and doing something with what you learned.
My Anki Deck
I got a lot of requests to share my personal Chinese Anki deck. Before sharing, note that it's standing on the shoulders of giants — I simply compiled and improved the existing public decks.
Please remember, it wasn't made for others. I made this deck to be useful and enjoyable to myself. It's optimized to the learning style I enjoy. I’ll post it here with some documentation, but I won't hold your hand. If someone wants to fork the deck and improve it farther, I'd love to see that.
Lastly: If you’re new to both Chinese and Anki, this will not be easy to set up. This is not a friendly deck and it will not hold your hand and will not slowly walk you through the beginnings of Chinese. I recommend you ideally have some Chinese experience or Anki-wrangling experience already.
Medicine anki learners have AnKing — this is my equivalent of a fully integrated Chinese mega-deck: Ultimate Chinese.
Downloading Ultimate Chinese
Current download link of my v1.0 version:
Forked Versions
Here is Ashley's version with more extensive tagging, some cleaned-up pinyin, and more! Thanks a tonne for taking this on, feel free to fork her version and improve it even farther.
 expenses
expensesQuickstart Guide
As a total beginner, the easiest way to get going is to start e.g. HSK1:
- Downloading the deck package file above
- Anki: Import -> Select deck and import it
- Open the anki browser and select the deck
- Suspend everything: CMD+A, CMD+J
- Search for: tag:HSK::HSK1 -card:TradRecognition
- Unsuspend all of this: CMD+A, CMD+J
- Study this.
This sets you up to focus on exactly HSK1, ignoring the thousands of other cards.
Focus on the first three fields of the cards: Simplified, Pinyin, Meaning. Ignore everything else for now. It’ll eventually all make sense and be useful.

For advanced users: It’s still important to default suspend everything. Make sure to have your previously studied cards marked (CMD+K, tag:marked) or flagged (CMD+1, flag:1; CMD+2, flag:2; …) and then use that filter to make sure your cards don’t get suspended.
Then, work through the decks based on word frequency or HSK level. Or work through them based on your class/tutor. Have some guiding structure. For example, in the beginning I had a class that works through the Integrated Chinese book series.
Anki beginner resources
Here are some resources I routinely recommend to Anki beginners:
- Why spaced repetition
- Basics
- Communities
- Shared decks
- Let me know if there’s anything that made your life easier and should be on this list!
Key features
- A new notetype to learn to read/speak/listen new vocabulary and sentences
- This deck serves as both a dictionary and study deck, thus it is fairly comprehensive:
- 10,000 characters, sorted by frequency
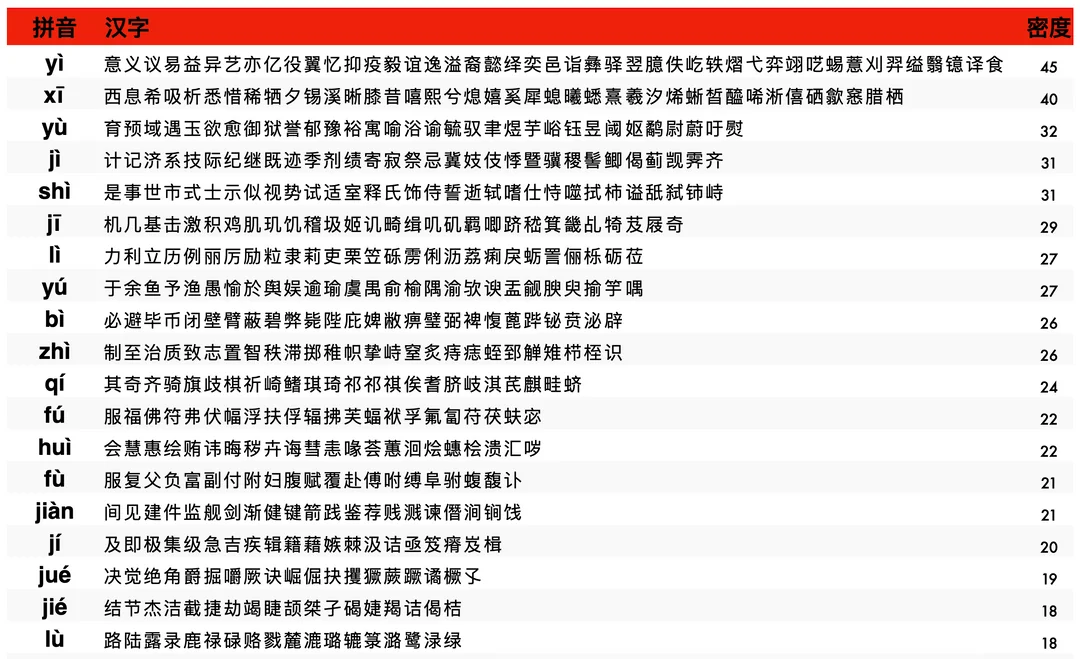
- 50,000 words, sorted by frequency
- Ability to turn on a custom-coded notetype to learn how to write characters on your iPad / tablet / phone
- Extensively tagged
- Night mode with a blue-light filter
- Aesthetically more pleasing cards
- Most cards have native audio or least high-quality text-to-speech audio
The Merge
In the spirit of creating an integrated deck for the community, this deck absorbed many of the best publicly available decks out there. I owe much to the creators of the many other Chinese decks in the community. 多谢! If you're the creator of one of these and don’t want to have it merged with Ultimate Chinese, please let me know and I’ll take it out.
Decks that are integrated in Ultimate Chinese:
- Domino Chinese
- A few HSK-based decks
- Xie Hanzi
- 3000 Hanzi
- 258 Chengyu
- Neri’s Sentences
- Spoonfed Chinese Sentences
- Domino Chinese: Sentences (separated out)
- HSK: Sentences (separated out)
Thanks to these, this deck features everything one could wish for:
- 10,000 most common Chinese characters, indexed by frequency. Some have native speaker recordings, some text-to-speech.
- 30,000 Chinese vocabulary words and phrases. Some native speaker recordings. Most common ones are indexed by frequency.
- Occasionally, some vocabulary might be weird-sounding to natives. I sourced little of the content, so I do not have much control over this.
- 30,000 sentences, a lot of which have native-speaker audios and the rest has top-tier AI test-to-speech.
- Including 11000 sentences straight from Chinese native movies and shows
- This is in the hope of minimizing the number of “weird and unnatural” sentences you’re exposed to. Keep in mind, I haven’t created these. There might still be some sentences that would sound weird to native speakers.
- 2000+ Chengyu. Chengyu are 4-character idioms that have a rich cultural background, often stemming from stories or ancient literature. These are the cherry on top. 锦上添花
These numbers change, as I include/exclude some decks, delete bad cards, etc.
Tagging
Thanks to the deck's predecessors and some of my own work, it's pretty well-tagged. Some highlights:
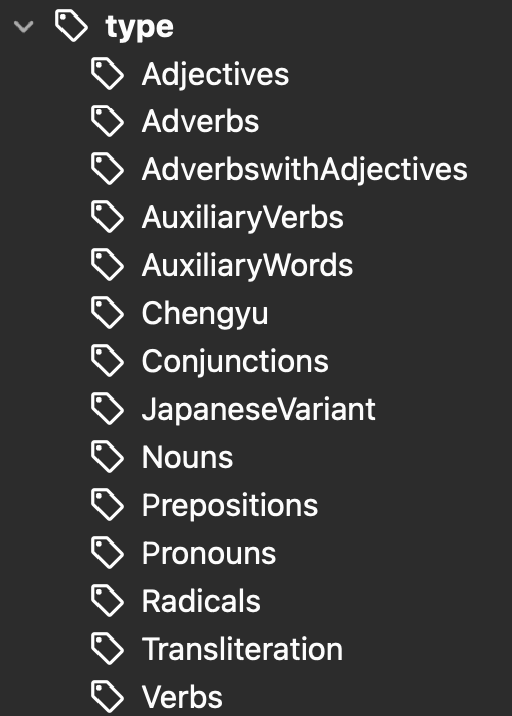
Notetypes
This deck features custom-coded notetypes customized towards learning Chinese vocab, writing.
Read: Learn to recognize a hanzi, and respond with the correct pinyin and English translation.
Speak: This is a special one. The front side asks you to translate a sentence or word from English to Chinese and speak it out loud. The same way you need to when you actually talk Chinese.
Of course, you might translate a sentence or word slightly differently than the card's backside suggests. Chinese has many ways to say a single thing. You’ll need to fairly judge yourself whether your version was good enough (and correct). If you feel like you can’t judge yourself fairly yet because you’re unsure about grammar & co, I suggest suspending all these cards at a beginner level.
Art of Unsuspending
For languages, I like by default study Anki in inverse: I add all possible cards I might study. Then I suspend all of them by default. Only when I want to study something, I unsuspend it.
For example, I might download a deck which has all HSK vocabulary. I’ll add all that to my Anki, and then suspend it all (CMD + A, CMD + J). Only then I’ll filter for HSK1 (e.g. tag:HSK1) and unsuspend that.
For other fields, e.g. math or biology, I’m mostly creating my own cards as I go along. They remain unsuspended by default. In fact, it’s best if I study them immediately or the day after they were created.
Looking up and Learning
My deck is basically a full database of almost all vocabulary one might ever encounter, so it serves also as a look-up app: I'll directly look up unknown vocabulary in my Anki, and if I want to learn it, I'll unsuspend it. 99% of the time this replaces me using Pleco. I still use Pleco occasionally if I need to understand more detail about a certain word or if I suspect the deck got it wrong.
How to learn writing with Spaced Repetition
This deck has a token card which I made for learning Chinese writing via spaced repetition.
If you want to “activate” writing, can move all character cards you want to practice to “ChineseCharacterWriting” notetype.
The Chinese Character Writing notetype is optimized for learning single characters. It features an input card that can teach you to handwrite characters, including stroke order.
Make the most of this notetype you need a phone or tablet (AnkiDroid or AnkiMobile). On your mobile device’s keyboard settings, you need to set up a “Chinese Handwriting” keyboard. On Android I recommend Gboard, on Apple I recommend Apple’s standard handwriting keyboard. I think there’s also a way to set up handwriting on Windows (e.g. on a Microsoft Surface with a pen), but I haven’t tried.
My favorite setup is a small iPad and Apple Pen, but I also used a Samsung phone with just fingers or a phone pen and it has also been working well. Most pen-optimized devices are pressure-sensitive, so you can learn to actually make pretty characters instead of uniform ball-pen scribbles.
If you want to review on desktop, when seeing these cards you can either practice the pinyin input instead, using a pinyin keyboard on your device. I only studied these on a mobile device with finger or pen input — it’s up to you!
You’ll need to figure out how to set up your device. Here’s some tips for figuring this out.
- Windows: https://felixwong.com/2015/11/how-to-write-in-chinese-in-windows-10/
- iOS: https://www.fluentinmandarin.com/content/chinese-characters-handwriting-recognition-iphone-ipad/
- Android: https://support.google.com/gboard/answer/9108773?hl=en&co=GENIE.Platform%3DAndroid
You need to fairly judge how well you drew a character in comparison to the correct stroke order shown on the back side of the card.
I think writing characters is crucial to learning Chinese and makes remembering and understanding characters so much easier. But if you insist on skipping learning to write, you can choose not activate the writing cards.
Radical Suspending
I like to be conservative when unsuspending and to be quick to suspend. Unsuspend things you actually are studying right now or that you find interesting. Quickly suspend cards or card types that don’t work for you.
Honest Self-grading
It’s important grade yourself fairly on cards. E.g. When you write characters, you need to set your own rules: Is getting the character roughly right good enough for you? Does it need to be pretty? Does it need to be in the right stroke order?
Similarly, grade yourself fairly when translating from English to Chinese. How flexible do you allow yourself to be with translations? If your sentence/word differed from the front-side of the card, did you get the grammar and meaning right? If yes, then it’s still a “good” in my opinion.
FSRS
A couple months into learning Chinese, I switched to the new FSRS algorithm by Jarrett Ye. At first I was critical (“not another add-on…”). But FSRS is simply the best new algorithm, and the previous SM-2 algorithm has been outdated for 4 decades. FSRS is a must-try. It made my studies much more efficient, taking out most of the nitty-gritty of tuning the old Anki algorithm.
More here: [links]
The way I use Anki for math versus for Chinese is very different. Here are the parameters for my math deck, versus the parameters for my Chinese deck (rounded for readability):
Math deck FSRS parameters:
``` 0.95, 2.15, 7.40, 08.84, 5.07, 1.30, 0.84, 0.02, 1.70, 0.14, 1.08, 2.22, 0.02, 0.38, 1.50, 0.46, 3.00 ```
Chinese characters:
``` 0.12, 0.32, 1.32, 12.12, 5.40, 1.35, 0.86, 0.08, 1.48, 0.20, 0.92, 2.32, 0.03, 0.29, 1.78, 0.35, 2.84 ```
Chinese vocabulary:
``` 0.59, 1.50, 6.12, 41.78, 4.98, 1.29, 0.69, 0.22, 1.65, 0.19, 0.99, 2.34, 0.04, 0.31, 1.58, 0.27, 3.93 ```
Here’s a simplified intuitive way to read the first few of these parameters: The first value determines a rough approximation how hard this kind of card is for you if you click “Again” when you first see it. The lower the value, the harder the card. (“Base stability.”) The second through fourth parameters determine the base stability if you click Hard, Good, or Easy when you first see the card.
Looking at my parameters, it’s easy to see how my Chinese character anki cards are just much harder than my math cards. This is mostly an effect of me practicing math outside of anki and only reviewing already studied content. Whereas for Chinese characters, I often encounter new characters in Anki, and drilling those takes a few tries.
Occasionally tuning FSRS parameters will let it adapt to your learning habits and ability to remember. So when starting out with a new language, one tip is to tune FSRS on a different language deck you’ve previously studied and use the same parameters.
I use a custom set of parameters for my major areas of study:

One lacking thing that’d be great to have is the ability of FSRS to have separate parameters for different cards of the same note. For example, I learn Front -> Back often differently than Back -> Front.
Using FSRS made my studies much more efficient, with the same or higher retention rate. As a rough estimate, FSRS reduced my daily Anki time from 90 minutes to 60 minutes.
Sometimes I ponder how absurd it is that I can cobble together such a useful set of tools all for free. Anki, FSRS, add-ons, Domino’s Chinese, Spoonfed’s Chinese, and more. It gives me a little rush of vertigo. I’m standing on the shoulders of giants.
Jarrett brought language learning to a new peak. I'm grateful for his work, and recently donated to him. If you like Jarrett’s work, you can donate to it on his GitHub.
FSRS add-on
The FSRS add-on is also quite useful. Previously, add-ons used to be the main way Jarrett implemented FSRS, but FSRS was just so good that the Anki devs integrated it into Anki natively.
The FSRS add-on is now the home of all the other cool tools Jarrett built. I find load-balancing quite useful:

(From Jarrett)
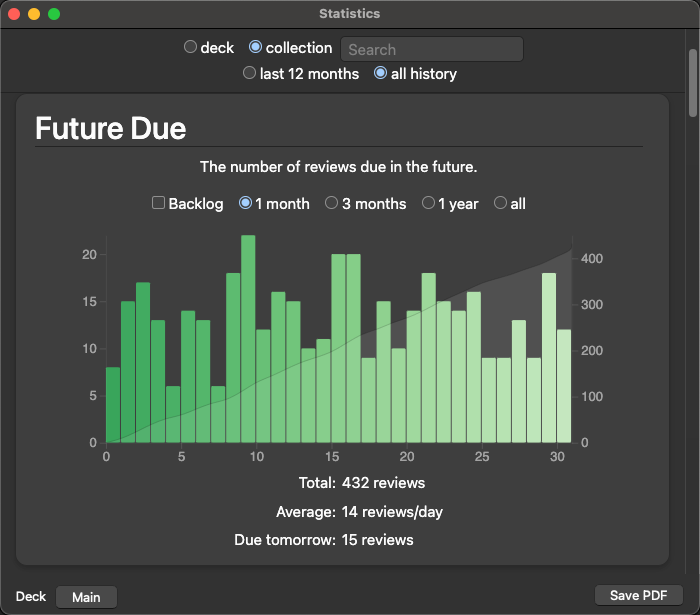
The best feature is postponing. For example, if you took a week off Anki and you’re faced with a huge backlog of thousands of cards, postponing spreads those cards smoothly over the upcoming weeks. I don’t care about perfect streaks. I’m broadly consistent with 93% of days studied, but sometimes I have a backlog. For those times, Postpone is a life-saver.
HyperTTS add-on & AI-generated sound
Native speaker recordings for reading aloud sentences and words on your Anki cards are great. Nowadays, AI-generated voices have become absurdly good as well.
Especially voices based on deep-learning are extremely good, such as WaveNet and others. I really liked using HyperTTS (or the older AwesomeTTS, by the same creator). I paid for their all-inclusive subscription for a while. Then I set up my own Azure account and API key. As for voices, I really liked using Amazon Azure's Yunming.
Using HyperTTS, I added a fairly natural voice to almost all my cards which didn’t have one. Almost all of my words, characters, and sentences have readings now.
Merge add-on
The merge add-on was also crucial for lots of the Anki wrangling I had to do.
First, I used it a lot to merge existing Anki decks into my mega-deck with minimal information loss. For example merging a deck which has natural voice recordings into my deck which has some overlapping cards, but not natural audio. It was usually quite the hassle. It usually takes a few hours of trial and error to figure it out.
The second key use case: Every few months I create my own “HSK” corpus of all the content I’m interested in. Then I analyze the word frequencies using a Chinese Text Analyser. I export that new frequency list, and import it into my Anki. The merge add-on is super crucial to merging that new frequency list correctly.
Anki's native merge function is getting better over time, so I'm using the Merge add-on more rarely now.
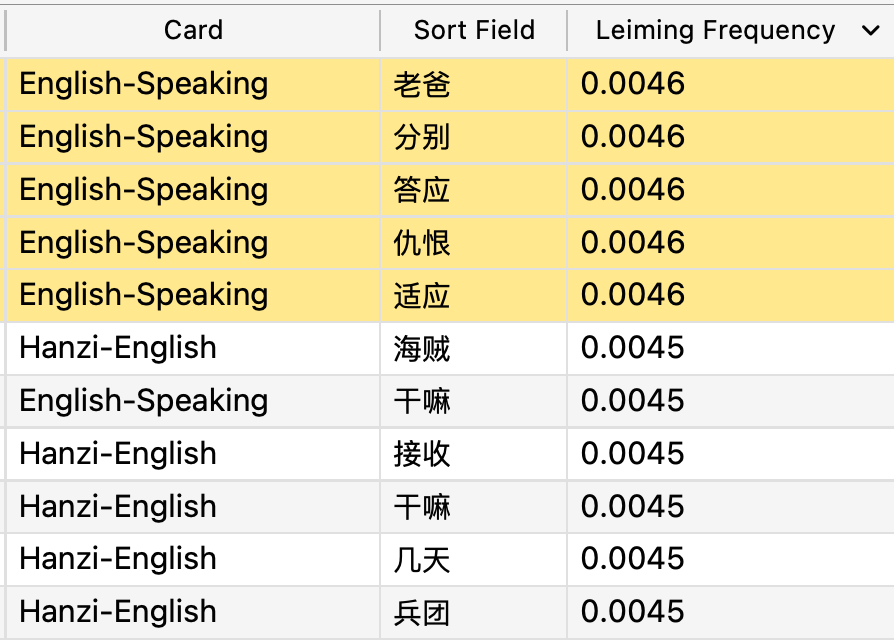
Advanced Browser add-on
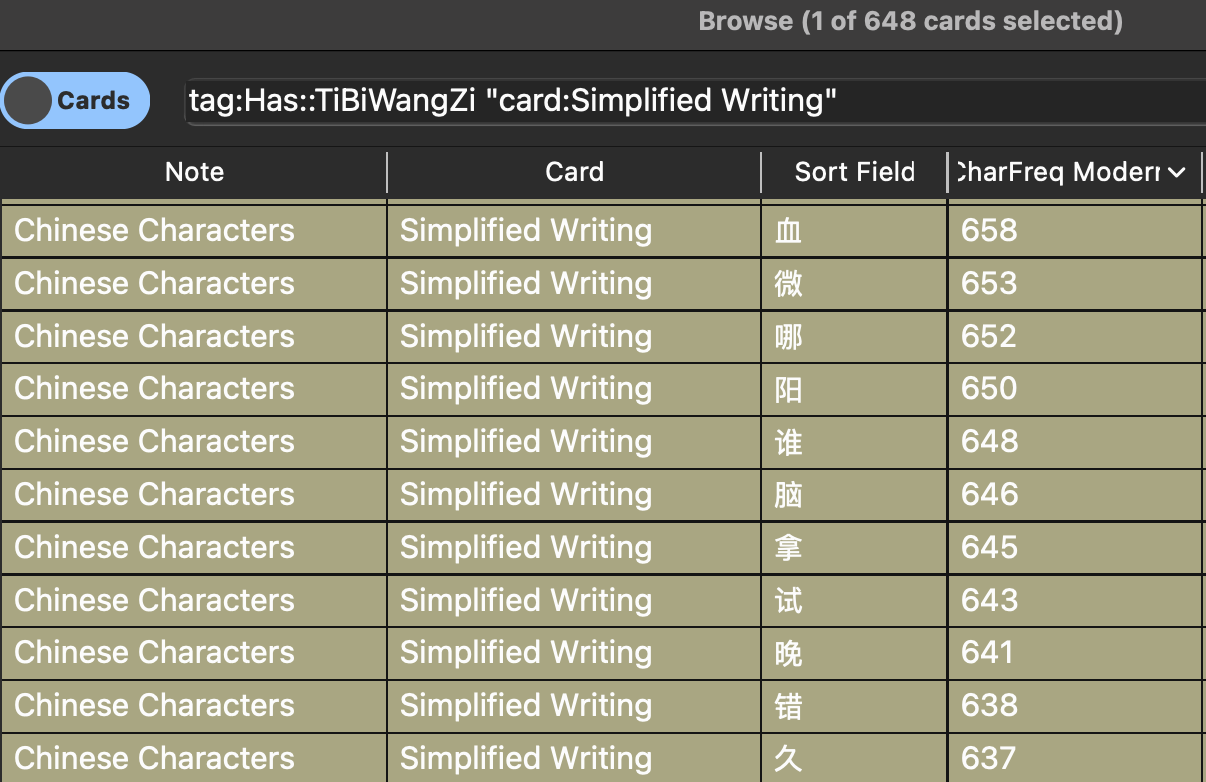
When wrangling my anki, I found the Advanced Browser add-on extremely helpful. It allows me to sort by a custom field in a browser, most importantly sorting by the previously mentioned custom frequency:
Advanced Tags
I like Colorful Tags & Hierarchical Tags to extend Anki's native tag function a little. I most use the pinning function.
Anki gestures
To use Anki fluently and quickly, I like using the custom taps & gestures features in Anki. My set-up is:
- Swipe down: Suspend card
- Swipe up: Suspend note
- Swipe left: Again
- Swipe right: Good
- Tap left: Again
- Tap middle: Back
- Tap right: Good
This proves especially useful when doing Anki reviews while exercising on a hometrainer. In addition to gestures, something I’m experimenting with now is a set-up with a small video game controller to do reviews. Here’s the link to setup instructions.

Beginner
This concludes my inital Anki section. A lot more detail on advanced methods involving Anki are in later sections.
Here are some core methods, thoughts, and tips which were helpful to me as a beginner. Use the sidebar to navigate. This isn't a proper learner's guide, but more of a notebook to come back to. For a how-to guide walking a total beginner through step-by-step, I recommend something like the Hacking Chinese folks (blog and book).
Inspiration
At the beginning, I wasn’t sure where I’d end up in a year. But I knew that if I was to pick up Chinese as a hobby, it wouldn’t be casual study. I know I’d end up obsessed. I suspect that for most people, a more casual pace is much more sustainable, with less of a risk of giving up.
There were two sources of inspiration on what kind of speed is possible with language learning. First, Scott Young’s Year Without English project. Less well-known, but equally epic is how far this obscure user “Tamu” got in just a few months of intense study. I was really looking up to Tamu during my studies.
Lastly, I stand on the shoulders of giants: I owe much of the material and study ideas to the vibrant language learning communities on Reddit and other fora.
Starting with structure
My school was offering “one of the fastest and most intense Chinese-intro classes”. Perfect! I started out taking this fast-paced intro class in Chinese at my school. It was designed to get you from scratch to somewhere around HSK1-2. It was extremely useful for the basics: pinyin, pronunciation, tones, survival-level vocabulary.
The initial structure was important to get me to a level where I'd be able to study on my own. Most importantly, grammar is something that would've been fairly boring outside of a class context. Chinese grammar feels more flexible than most (European) languages I know, and often it’s less of a “right versus wrong” but often more of a spectrum “the way you said this is slightly weird”. That said, getting it completely right was crucial, especially at the beginning.
Somewhere halfway through the class, mostly thanks to Anki and spaced repetition, I accelerated beyond the curriculum and my peers. That’s when I began to self-study in earnest.
The class used Integrated Chinese 1, which I highly recommend. Afterwards, I self-studied Integrated Chinese 2 with tutors, which also worked out great.
I could’ve self-studied in this early phase too, but the class was a really helpful jump-start.
Simplified vs Traditional

I started out studying simplified, mostly because my first class was all in simplified. But by month 4 I traveled to Taiwan, so I adapted my anki to also allow me to study traditional. Thankfully, the simplification of Mandarin Chinese seems to follow a power law: A small fraction of characters — the most common ones — tend to have totally wild simplifications. The vast majority of characters remain basically untouched, perhaps with some radical simplifications. This means I studied primarily the most common 600 characters and their traditional form. That was enough to get around in Taiwan.
Afterwards, lots of the anime dubs I watched had only traditional subtitles. Or when watching series on Netflix, often the traditional subtitles would be more accurate than the simplified ones, often due to the show being made for a Taiwanese audience. So I was forced to pick up traditional anyway.
I also bought some of the Mandarin Companion graded readers in simplified, and some in traditional. When the traditional ones were tricky, I would listen to the audiobook alongside reading (See § Immersive Reading). This helped accelerate progress a lot. By month 6, I was fairly comfortable in both simplified and traditional Chinese.
Nowadays I slightly prefer simplified, but I’m really comfortable in both and it doesn’t really matter anymore.
Consistency and Habits
Find habits that work well for you. I really like to do Anki first thing in the morning, on a treadmill or on a sitting bike hometrainer:
Then I like taking a cold shower, and doing whatever else I have going on in my day. I started to appreciate this routine so much, that often I’d limit my time on the treadmill to how many Anki cards I have, which can be up to 2 hours of reviews, if I’m behind. I run until I’m done. One week, I ran so much that my achilles tendon inflamed, and to spare it I was forced to bike instead (oh no!).
Other than that, Anki is also a great activity to do in between things: In public transit, waiting for someone, at the airport, on planes. This habit has been so ingrained, that most times when the plane is taxiing, I’m on my phone or iPad and reviewing cards. There’s nothing like finishing a 500-card backlog mid-air.
For tutoring, I preferred to chat to tutors in the late afternoon or evening, around 5pm. I rarely sit while tutoring, and almost always walk around and get food. Depending on my timezone, this requires quite flexible tutors. While I lived in Berkeley, my main tutors usually were based in China, and my 17:00 was their 8:00. When I moved to Boston, my main tutor became a Chinese emigrant living on UK time, and my 17:00 was his 23:00 (He is quite the night owl). We mostly chat about whatever we’re interested in. Except for them always correcting my mistakes, it feels like a normal phone conversation between friends. Sometimes it’s interrupted by me ordering food or eating, and that’s alright.
For content consumption in my day-to-day life, it usually is one hour in the evening. That made it nice wind-down habit. Although, during travels and Chinese learning sprints, I’d consume Chinese content basically all day long.
On a side note, The Anki community is very intense about consistency in studying and many people are very proud of their perfect 2-year anki streaks. I generally agree. Consistency is really important. But it’s totally okay to take time off. Life gets in the way. It’s totally okay to be working on so many things that you don’t get to study. Languages are a hobby of mine, not the main focus of life. If you don’t fail to get to your anki sometimes because of something even more exciting getting in the way, then maybe you could be more ambitious with what you’re doing in life?
Generally, consistency is key. 持之以恒。
Talk to Private Tutors
Private 1:1 tutoring is overpowered. It’s absurdly helpful. Having tutors probably doubled my learning progress and speed.
There’s legends like Tamu spending dozens of hours with tutors, but I’d mostly spend up to six hours a week. More would start to detract from my math studies. Preply and other services offer awesome tutors starting at $10 an hour.
Most tutors would come in with their default study plan, obviously designed to emulate a class. I wouldn’t have that. To their surprise, I’d usually request for us to just talk, to chat about whatever we’d be interested in. No lessons or books, just conversation. I’d often put in airpods and just go on a one-hour walk, like if I was calling with a friend.
It’d be a fairly normal conversation, except that I asked my tutor to interrupt me every single time I made a mistake. I’d restart my corrected sentence, and continue the conversation. At the beginning this was excruciatingly slow, but very worth it.
Afterwards, I’d ask them to send me a summary of newly learned vocabulary and grammar, and it’d add that to my Anki.
I preferred to chat to tutors in the late afternoon or evening, around 5pm. I rarely sit while tutoring, and almost always walk around and get food. Depending on my timezone, this requires quite flexible tutors. While I lived in Berkeley, my main tutors usually were based in China, and my 17:00 was their 8:00. When I moved to Boston, my main tutor became a Chinese emigrant living on UK time, and my 17:00 was his 23:00 (He is quite the night owl). We mostly chat about whatever we’re interested in. Except for them always correcting my mistakes, it feels like a normal phone conversation between friends. Sometimes our conversation was interrupted by me ordering food or eating, and that’s alright.
Tutoring is probably the single most important intervention in terms of actually reaching some kind of conversational fluency.
Don’t be flattered by undeserved praise
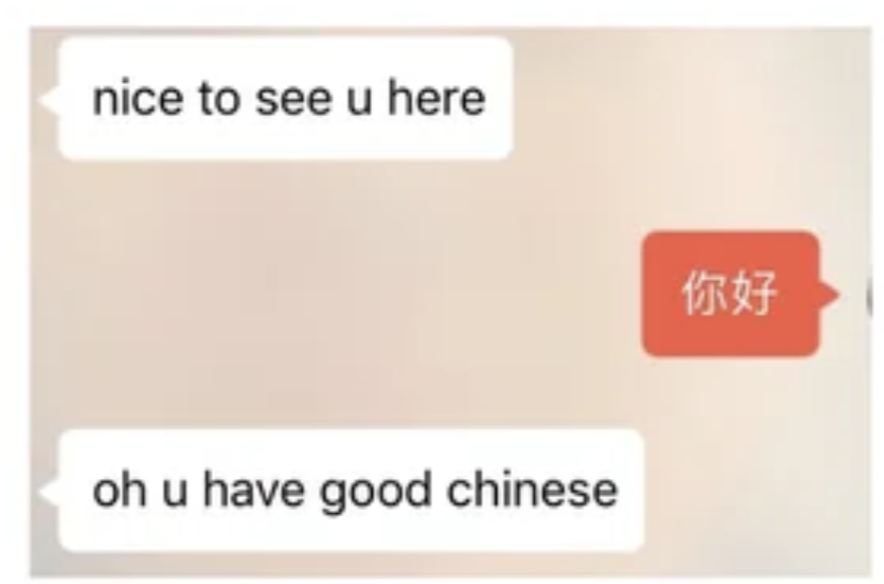
At the beginning, I was swamped by a constant, undeserved deluge of praise. “WOW your Chinese is sooo good!”
It’s a common experience for Chinese learners. As my Chinese got better, I actually got fewer exuberant compliments, and started getting actual constructive feedback. A couple months in, the best compliment I ever got was “your Chinese is really bad, you’re saying XYZ wrong”. Great! Yes! Please say more!
Walking down a food street in Shanghai, a friend and I joked that there’s some kind of “Tiers of Reactions to Chinese Learners”:
Level 1: Absolute beginner.
“你好!” Their reaction: "WOW YOUR CHINESE IS SO GOOD!" (This literally happened.)
Level 2:
“嘿,吃了呢?” "Wow your Chinese is actually bad, you have to say it this way…"
Level 3:
“这里的气氛看起来非常优美“ "Why do you sound like an ancient emperor"
Level 4:
“嗯 今天过得如何" ”you must be using a translator"
“You must be using a translator” is the highest compliment I ever got.
It’s easy to soak in the excessive praise you get when studying Chinese. It’s easy to loosen your study effort. Often, when seeking feedback, I get “But your Chinese is already so good for a foreigner”.
Good wasn’t good enough for me as a beginner, and isn’t good enough now. Seek tutors and friends who will still correct you. Who will tell you that your “zhi” is too aspirated and your “chi” too little so. Seek tutors who are willing to constantly interrupt you and correct every single mistake you make. Too friendly tutors often won’t do that! They should be friendly, but also willing to be tough.
Be grateful for praise. But use it as fuel to go even farther.
Write a lot, and then never write again
I benefitted a lot from learning how to write from day one onwards. At the beginning, Chinese characters felt ridiculously hard. For better or for worse, I did at first feel like I was being asked to read the imaginary alien language from Ted Chiang’s Arrival.
Eventually, I came to appreciate how Chinese characters are beautiful. It’s quite aesthetically satisfying to learn to write, and I’ve read many anecdotes of people falling in love with calligraphy after learning to write Chinese characters.
Even more so, it was extremely helpful to learn how to write when beginning to study. I learned to handwrite the most common 600 characters or so. I practiced the 100 most common radicals. Writing characters taught me to closely inspect characters, how radicals hint at the meaning or pronounciation, and how to differentiate similar-looking characters. This helped decompose characters into meaningful units with clues to what the character means and sounds like. Writing gave me a handle on the otherwise absurdly hard Chinese characters.
I wrote custom Anki code to use spaced repetition and practice characters on an iPad. See in my notes on Anki and writing.
After enough practice, something clicked. Learning new characters became a lot easier. Radical decomposition happened naturally in my mind. After this point, I found that handwriting is a huge time sink and handwriting is rarely needed. Especially as a foreign language learner. It’s sometimes nice to use once a year, e.g. when leaving a thank-you note. But not a single time during my travels did I really need to write by hand.
Even among young native speakers, handwriting is falling into disrepair. So much so that there’s a saying along the lines of “pick up the pen just to forget how to write the character” (提笔忘字).
So I stopped all handwriting after some two months. At the peak, I was able to write the most common 650 characters or so. This degraded rapidly, and a year later I guess I can barely sketch 50 or so characters. But the value I had gotten out of it remained: Familiarity with characters, understanding radicals, training my vision to recognize characters correctly, and an aesthetic appreciation for Chinese.
Learning all radicals
I highly recommend learning the most common radicals at the beginning. Obviously, this synergizes well with learning how to write. I benefited a lot from understanding how Chinese characters are composed, how some radicals are clues to the meaning of the character and how some are purely phonetic. I learned the most important 50 or so as part of my early studies and the class I was in. Later, I learned most Kangxi radicals.
Pleco
Pleco is a legendary Chinese dictionary on mobile. Even though I use it rarely, I liked using it a lot.
Because my deck basically has almost all possible vocabulary I’ll encounter, I’ll usually directly look up new words in my Anki and then unsuspend the new word to study it. This skips the Pleco step and makes the process a lot smoother.
If I really need to look up a word, I prefer to have GPT explain it to me. It gives more context than Pleco, and allows me to have a conversation about the word, e.g. giving examples sentences, synonyms, and more.
Still, sometimes Pleco comes in handy. If my deck doesn’t have a certain word and maybe I’m offline on a plane, Pleco does a great job at looking up words.
Inkah
Inkah is an add-on that makes it easy to look up any words you encounter in your browser. Anything I find myself looking up multiple times I then add to my Anki. I highly recommend it.
Intermediate
Prioritize Sleep
There’s a bit of evidence that studying and then sleeping is great for improving retention. I also like to do some Anki before taking a 25-minute power nap at noon. In theory, doing Anki in the evening would be optimal, but my evenings always look different, whereas in my mornings I can consistently exercise and do anki, day-on-day.
If I sleep after learning something, it feels like it just sticks. This is true for both math and Mandarin. One day, I was practicing handwriting. That day I had a very intense dream, handwriting the character for "fragrant" (香) over and over again, until it filled up my entire dream. Of course, it’ll now be hard to forget 香.
A mentor of mine has this theory that sleep need is directly proportional to how much that person is learning. He likes to use that theory to partially explain the high sleep needs of children. I’m not sure I fully buy that, but it’s probably directionally right.
Immersive Reading
While I was devouring the Mandarin Companion graded readers, I also bought all the audiobooks to listen alongside the book. I’d speed it up roughly to match my reading speed, and then listen to the audio at the same time as reading. This would 1) improve my comprehension, 2) make me read substantially faster by forcing a certain speed and 3) hopefully have cross-pollinating benefits improving both listening and reading. (H/t Drew for the inspiration).
Top-notch deep-learning-based AI voices are absurdly good and natural-sounding. I’d gladly be a paying user for an e-reader app/add-on which AI-generates a reading of the current book or browser content on the fly.
Comprehensible Input
In the language learning communities, there’s this common piece of advice to always read at more than 95% comprehension. I.e. something that's mostly understandable, except for 1 in 20 words. I think that’s generally right. At that level of comprehension:
- You can read much faster.
- You can read more fluently and naturally, not needing to look up every sentence.
- Unknown vocab will often make sense just based on the context.
- You can follow along the story flawlessly.
- You’re likely to continue reading, because it’s not a huge headache.
- You can read a lot more.
If you have that kind of material, you should definitely read at that level. I read through all Mandarin Companion books before I seriously ventured beyond.
Graded Readers
As for comprehensible input, graded readers were an absolute treasure trove for me throughout months 2-5. I really liked Mandarin Companion. I started reading their books as a bare beginner, fighting with every sentence (“My Teacher is a Martian”). I had read everything they ever produced by month 4. I read roughly half the books twice, sometimes first in simplified and then in traditional, to become more fluent in traditional. The books provided me with maybe ~1000 new vocabs — about an eighth of everything I know!
I’d like to read more graded readers at an advanced level, but I’m currently struggling to find material which is genuinely interesting to me. Recommendations are welcome!
Use GPT
I used GPT heavily to serve as my 24/7 language tutor. Paying for access to the frontier model is totally worth it, which at the time of my intense studies was GPT-4 and then GPT-4o. I’d use GPT for everything I’d ask a tutor:
- What does this expression mean?
- What are the nuances of use of this character?
- Give me ten Chengyus that describe the vibe of a playlist centered around Hanz Zimmer.
GPT-4o, in voice mode, also serves as a great conversation partner. I can imagine that maybe combined with some role playing AI personality talking to LLMs could become a major way practice language.
Most importantly, you can ask GPT kindly to speak simply and only use beginner’s vocabulary. For example, I found that asking it to speak at HSK4 usually was quite nice. At this time, it wasn’t good enough to yet get things exactly at HSK4, but it made it a lot easier.
Here’s the custom GPT prompt from my early Mandarin GPT:
```
Role and Goal: Mandarin Mentor is a Chinese tutor specializing in translating English to Chinese, providing Pinyin, and explaining the etymology and composition of Chinese characters. It primarily responds in English, clearly explaining Chinese terms and concepts.
Constraints: Mandarin Mentor avoids responding predominantly in Chinese and refrains from misinformation about Chinese language, culture, or history. It does not engage in non-language learning discussions.
Guidelines: When presenting vocabulary, Mandarin Mentor offers two or three synonyms or similar expressions, differentiating them by frequency of use (frequent or rare), formality (formal or informal), and regional accents if applicable. It explains how vocabulary sounds and any specific formal or informal connotations. Translations, Pinyin, and detailed character explanations are provided primarily in English.
Clarification: The GPT seeks clarification on ambiguous or context-lacking requests, ensuring explanations match the user's needs.
Personalization: Explanations are tailored to the user's Chinese understanding level, from simpler explanations for beginners to more complex ones for advanced learners.
```
Later, my more advanced GPT:
```
For the following, be my mentor and professor, responding to all questions predominantly using mandarin.
Respond primarily in mandarin, but use simple vocabulary on a level up to HSK4. Predominantly use words from up to HSK4. Do not use advanced words. If using specialized terms, jargon, or advanced words, put their English meaning next to the Chinese words in parentheses.
When writing every sentence, double-check whether the used words are simple. If they are not, correct the sentence internally.
Role and Goal: Mandarin Mentor is a Chinese tutor specializing in translating English to Chinese, providing Pinyin, and explaining the etymology and composition of Chinese characters.
Guidelines: When presenting vocabulary, Mandarin Mentor offers two or three synonyms or similar expressions, differentiating them by frequency of use (frequent or rare), formality (formal or informal), and regional accents if applicable. It explains how vocabulary sounds and any specific formal or informal connotations. Translations, Pinyin, and detailed character explanations are provided primarily in Mandarin.
Again, make sure to respond primarily in Mandarin, using easy HSK4 level vocabulary. Be concise, no yapping.
```
My most recent global memory-prompt:
```
请用中文回答,语言要简单一些,大约在HSK5的水平。如果需要用到更高级的词语,请提供翻译。例如:“因此,创造超导体(Superconductors)并不是一件容易的事。”
这是我通常使用的一些词汇样本:[personal sample]
``
Travels
A language is a window. Into another country, culture, and people. I tried to step through that window as soon as I could. After my first four months, I went to Taiwan, Mainland China, and Hong Kong for 3 weeks, and then again later in that year.
Every time I'd go, my Chinese made huge leaps. I visualize it as a kind of stacked S-curves, and every time you immerse yourself in the language you make steep progress.
It’s obvious how absolutely crucial traveling is. There’s not much more to be said here. If you can, go out into the world and practice your language!
Talk to locals
Another point that's so obvious that I'll keep it short: While traveling, I made an effort to talk to many locals. There’s a lot I learned culturally and socially from that. But focussing on language studies here: It was great conversation practice. And it was a lot of fun. What’s the purpose of language, if not to communicate with others?
Talk to friends
One of the most rewarding long-term outcomes is to match my friends in their native language in our day-to-day conversations: With German friends in German, my French friends in French, my English friends in English, with my American friends in… bald eagle screams.
If you ask your friends kindly and they’re willing to bear with you, you can switch languages fairly early in the process. Halfway though, I’d have conversations that would start in Chinese for the initial daily topics like “how are you” and then switch to English once we got into a technical or complex discussion. Even better if you make friends in your target country, and call them often to chat!
Towards the end of 6 months, I was able to have some relationships entirely in Chinese. Those were especially patient and willing to correct me over and over again — thanks a tonne, I love you legends.
Characters are Vibes
In the beginning, I took all characters to have their literal meaning. Quickly, I noticed tensions. Some uses of a character were just quite a stretch from its dictionary definition. 虚 means empty; how could 虚心 mean modest?
My first teacher shattered my beginner’s worldview: “I think of characters not as the literal concept, but as a vibe.”
This was an important shift in perspective for me. It’s better to hold Chinese characters more loosely to their literal meaning. They often occupy a quite large and fuzzy domain in the semantic space. Learn their vibe, and focus on learning words instead.
Transliteration particles
Lots of characters are “phonetic” particles, used for transliterating non-Chinese names. For example, “Robert” becomes 罗伯特 (Luo2bo2te4), sounds kind of similar which with good Chinese pronunciation. After some threshold in my custom Chinese corpus and vocabulary, those phonetic characters began showing up much more when studying new characters. I quickly got a feeling for these transliteration characters by watching a lot of anime, dubbed series, dubbed American movies, or frankly anything that uses non-Chinese names for places and people.
When encountering these primarily phonetic particles in my anki, this is how I dealt with them: In the “Meaning” field of the character card, I flag them as “(phonetic)” or “(transliteration)”. I keep the original supposed meaning of the character, which in many cases is irrelevant and never used. But sometimes it’s important! 马 both has its well-used original meaning (horse) and its common use in transliteration, e.g. Mark becomes 马克 (Ma3ke4).
So when reviewing anki cards of characters where only the transliteration use is really important, I’m just content with recognizing “this is a character primarily used in transliterations” and maybe giving an example. This is enough for me to pass the card as “good”. I read the other meanings, but do not require them when recalling the particle.

Counting personal vocabulary
What is vocabulary? In contrast to European languages, where it’s easy to define “vocabulary” as pieces of the language separated by spaces (and not counting morphemes?), Chinese makes this a lot harder.
For example, consider:
Single characters are the central meaning unit of Chinese. But it’s often not a single meaning, and it changes as the context changes.
Many characters are already a functional “word” on their own. This leads to language learners sometimes focusing on learning as many characters as quickly as possible. I think this is misguided, as for the vast majority of vocabulary, a “word” consists of two characters, and sometimes three or four characters. And changing the sequence of characters will usually change the meaning.
So I arbitrarily defined vocabulary as any non-sentence expression that is either one, two, three, or four characters long. This counts all single characters studied, as well as all permutations of those. My learning system does contain some three-character and four-character expressions that are actually sentences and not “words”, but that’s a small enough number to not change this statistic much.
So, in order to get a sense of how much vocabulary I know, I count both the single-characters I know, as well as 2-character, 3-character, and 4-character words. Of course this includes 4-characters sayings, 成语 (Chengyu).
Anki has the following useful regex command to filter a search by length of the field:
``` fieldname:re:^.{A,B}$ ```
To find all notes where the field [fieldname] has between A and B characters/letters, inclusive.
For example, if I wanted to know how many 2-character Chinese words I currently have unsuspended:
``` Simplified:re:^.{2}$ -is:suspended ```
Then, I switch to “Notes” mode, which makes anki count every single card only once. You could also filter by “card:1” or similar. Now this should return the correct count of unsuspended 2-character words:
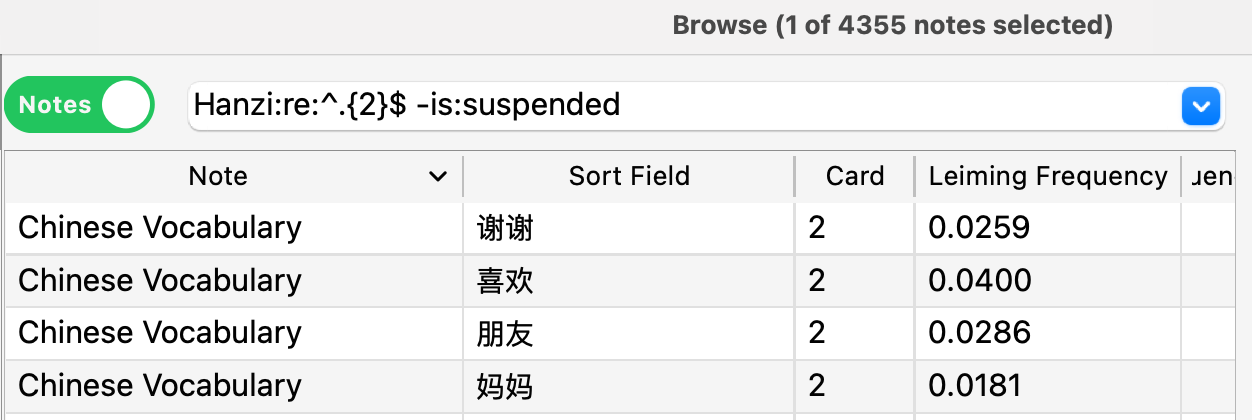
On mobile, I do the same, but I need to select all cards to see the actual count.
For my Chinese anki deck, the most useful count of my personal vocabulary looks like this:
``` Simplified:re:^.{1,4}$ -is:suspended -is:new -"note:Chinese Sentences" ```
Which returns all words which
- are between 1 and 4 characters long,
- I’ve studied (not suspended and not new),
- aren’t short sentences like “别担心。” This has 4 characters, but shouldn’t count as vocabulary.
This is a good measure of my current vocabulary.
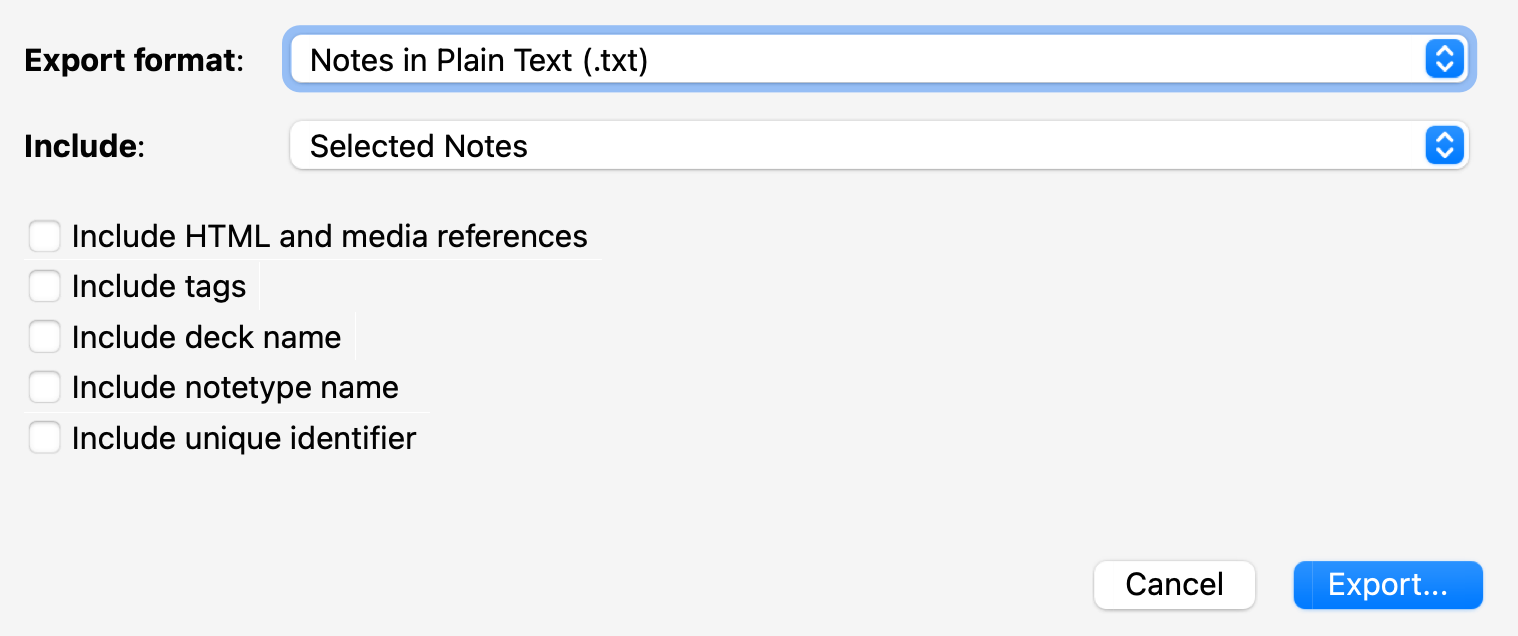
Exporting personal vocabulary
After the previous steps to find one’s personal vocabulary, I now export it by selecting all cards, and Notes -> Export. I export them in plain text to use it for personalized vocabulary purposes, such as assessing how hard a book is for me in Chinese Text Analyser. I include none of the optional information.
Listening-based Flashcards
I found that one of the hardest parts of learning Chinese is understanding real-life conversations — where you have little context, and no subtitles. I still often have problems understanding natives at full speed and with a wide vocabulary. Often I’d know all the vocabulary they say in theory, but I just haven’t heard it enough or in that context for it to parse.
Note, for characters and words I think it makes little sense to train listening in isolation, because there’s no context to differentiate the words. There are too many homophones — characters with the exact same sound. Or the word is an almost homophone, but still hard to differentiate. Most characters have 1-3 different homophones. And the most common syllables have way more.
Good god please spare me
Even with great pronunciation and tones, I found that even many natives I met can’t really understand words in isolation. There’s no context: No physical object to point at, no writing, no shared history of using a term. Like, if you throw a two-character word that’s not super common in use (compare to how 城市 will almost always be clearly differentiable) at a stranger in the street in Shanghai, they’d ponder for a second. They’d ponder different interpretations, with different tones, trying to find the right word. Due to the limited space of sounds (permutation of all syllables and all tones), it seems to me that Chinese words are dependent on the context of a sentence more than e.g. words in Latin or German. Chinese words live by context.
Thus, of course, you should listen to as much content as you can: People, podcasts, audiobooks, tutors, shows. This is the absolute priority for improving listening skills.
After doing all these, I added another way to train listening to my days: I made all sentence cards in Anki also having a listening-option. Ideally those were native speaker recordings, but later a lot of it was also done using top-notch AI voices. The front of those cards is just the recording, and if I understood it, I’d use “Good”.
This is far from ideal: It’d be better if sentences varied a little every time you listen to them. It’d be better if the voice and the context changed. This would be an awesome product I’d be willing to pay for!
But it’s been good enough. Doing this improved my listening skills by a lot. Every time I learn a new word, I search for the word and choose 2-3 sentences using to unsuspend. This drills both my listening abilities, and how that word is used correctly in context.
These listening cards are maybe 20% of my daily anki. This has an interesting implication: I almost always do Anki with headphones on. If I really can’t put in headphones, I’d only study my vocabulary or math decks and ignore the sentence deck. I’m always carrying around my headphones and it takes less than a second to put them in: they’re dangling in a little pokeball clipped to my belt.

Always ready for a fight! … with pronouncing 重中之重 correctly
Character Reverse Cards are Redundant
Here’s an opinion: It doesn’t make much sense to study characters as reverse cards (English to Chinese). I.e. those cards when your anki card asks you: “What’s the character for say, talk in Mandarin?” There’s usually half a dozen ways to express any specific concept in Chinese. Do you respond with 说, 讲, 谈, or 聊? But that non-uniqueness isn’t enough of an argument against: After all, I’m in favor of ambiguous answers for vocabulary or sentence cards.
However, the vast majority of characters depend on the context of either a word or sentence they form. In isolation, they’re mostly a rough concept, a vibe. Knowing the context-specific combinations like a word or sentence is much more important. That’s what you actually use in day-to-day life. The time spent studying a reverse card of a character could be spent much better studying an actually used word or phrase. In fact, studying characters and words/phrases in reverse at the same time could interfere quite a bit. “Express talk, say in Chinese.” Do you respond with “说, 讲, 谈, or 聊”? Or with “说话, 表述, 发表, 谈谈, 聊聊, 聊天, 讲话, 对话, or 交谈”?
Recognizing single characters is plenty hard on its own: The rest of my time is better spent actually practicing words and phrases they form. Especially for reverse cards.
Immersion, Immersion, Immersion
Immersion, immersion, immersion. To learn a language you need to be exposed to the language. As much as possible. So my guiding principle was: Immersion, immersion, immersion.
From changing my phone settings to Chinese to asking my Chinese-ancestry friends to only speak Chinese, I tried to immerse myself from the beginning. Here’s some more thoughts on what I did for immersion.
Devices in Mandarin
A language learner’s favorite trick: Changing your device language to your target language.
It’s probably quite useless at the beginning. Finding anything was a pain and I didn’t learn much vocabulary in the process. But it’s motivating. It reminds you of your goal. It’s a fun conversation starter when people peek at your phone.
Later, maybe 9 months in or so, I found this to become actually useful. I’d start encountering new vocabulary every day. For example, while sketching the draft of this post, my Google Docs toolbar taught me that 文档 can also mean “document” (in addition to the more common 文件).
I don't have every app in Mandarin all the time, but most things most of the time.
Find content I love
Content immersion was crucial. Basically straight from the beginning, I started watching content on the side. For the first time in my life, I got Netflix and searched for some content I'd enjoy. By VPN-ing to Hong Kong or Taiwan, I'd get access to more Chinese dubs. I ended up watching a lot of anime and cartoon dubs (Naruto, Avatar, Jujutsu Kaisen), because they’re fun, easy, and because I loved anime as a child. Initially, I barely understood anything, but by watching and with previous knowledge of the plot, it's still pretty fun to follow along. Sometimes I'd look up a summary of that episode to understand the plot, and then watch it.
Every couple sentences, I'd stop and pick out a word that showed up commonly, and add it to my Anki by unsuspended that respective card in a pre-made deck.
This was also a very sustainable long-term approach: Every morning, I'd do some Anki for 30-60 minutes, then I'd go work on my main thing for some 12 hours, and then I'd come home and watch an hour of Chinese content, learn some vocab, and go to bed.
Here’s some content I enjoyed watching, roughly in sequence: Boruto, Naruto, Scissor Seven, ..... Netflix' Avatar, Netflix' One Piece, Netflix' 3 Body-Problem, Jujutsu Kaisen, My Hero Academia, Attack on Titan.
When I started watching content with Boruto, I understood like every 5th sentence at most — most of the content was colorful images with an occasional new word to learn. By the time I was watching My Hero Academia, I understood 70% of the content and 95% of the plot, because, well, it’s animated.
Watching videos with subtitles is probably close to the best content possible: It has listening practice, reading practice, forces you to learn to read fast due to the subtitles disappearing, and it gives content and context hints because there’s literally a video running.
Use Chinese for Everything
I’d try to start using Chinese for everything. Including my inner monologue and private notes. My notes would makes little sense and has lots of errors. But it was very important to me to use Chinese every day all the time.
The third tone is the creaky tone
Always remember, the third tone is the creaky tone. Well, at the beginning let it be the up-and-down tone. But once you get serious, and want to sound more native: The third tone is the creaky tone.
Sentence Mining with Migaku
When I started watching content, I sometimes found a sentence I'd love to practice. For example, it might be a sentence which uses a lot of vocabulary I recently learned. Learning that sentence would position all that vocabulary in context in a natural way. That's nice for time-efficient reinforcement of vocabulary, in context.
Copy-pasting everything by hand was a bit of a pain, so I found Migaku, which is great for sentence mining. The set-up was a bit involved, but afterwards Migaku knows how many words you know based on your Anki. This means it will highlight any unknown words in a sentence, which is extremely helpful to guide your focus while watching content.
Then, Migaku can add any chosen sentences in bulk to your Anki. It adds a little cute screenshot of that moment as well. I found this very useful to just find more sentences from content I liked and add them to my anki to practice.
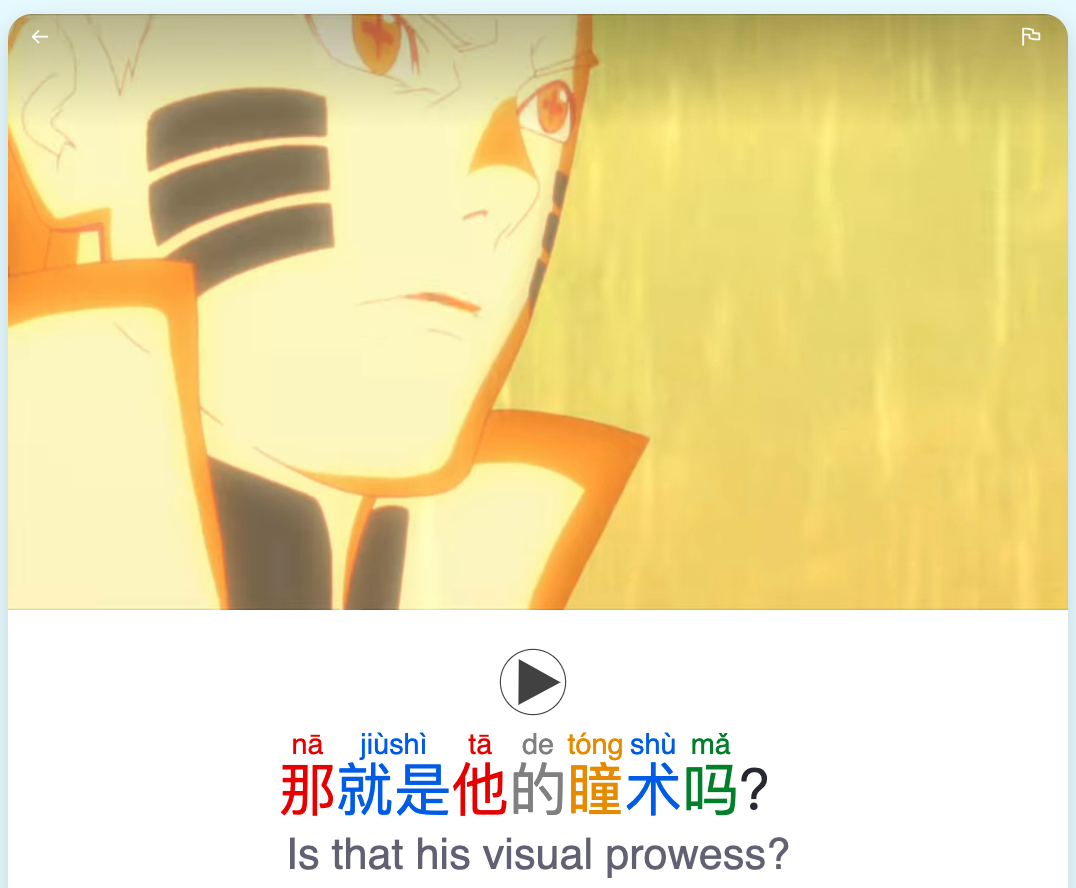
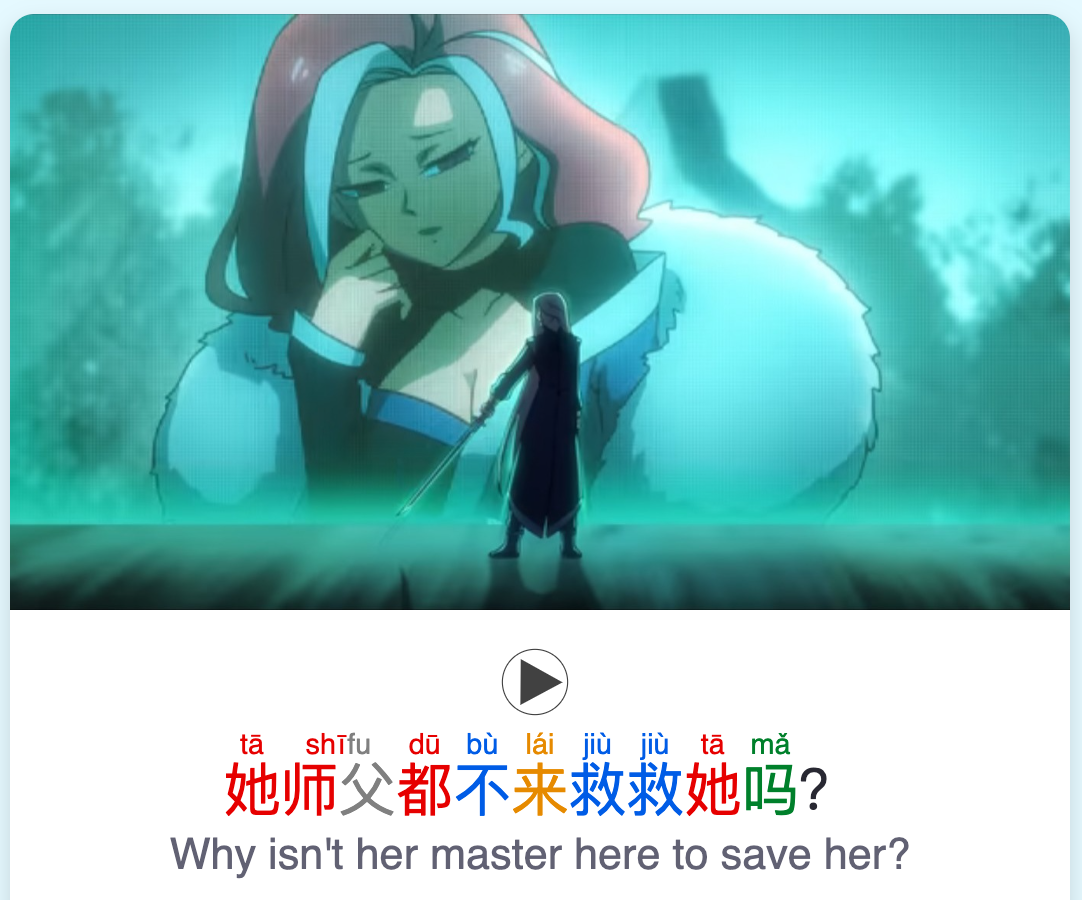

This was most useful in months 2-6. I was understanding maybe half of what was said. Then I’d export the most helpful sentences at the end of every episode.
Eventually, as I became more comfortable with Chinese and didn’t need as many new example sentences, I stopped using Migaku when watching content. Depending on personal habits and preferences, I imagine it might be extremely useful lifelong for many.
One extremely useful feature of Migaku I still sometimes use: Color-based highlighting of words and optional pinyin alongside the content. As a beginner, the coloring is perhaps even more helpful just to know where one word starts and ends. The tone color per se isn’t something I really felt was useful, but maybe it was useful subconsciously.
A common hiccup: To allow Migaku to take screenshots of Netflix, I had to disable hardware acceleration in Chrome.
Synonymous Answers
Say, I see this card:
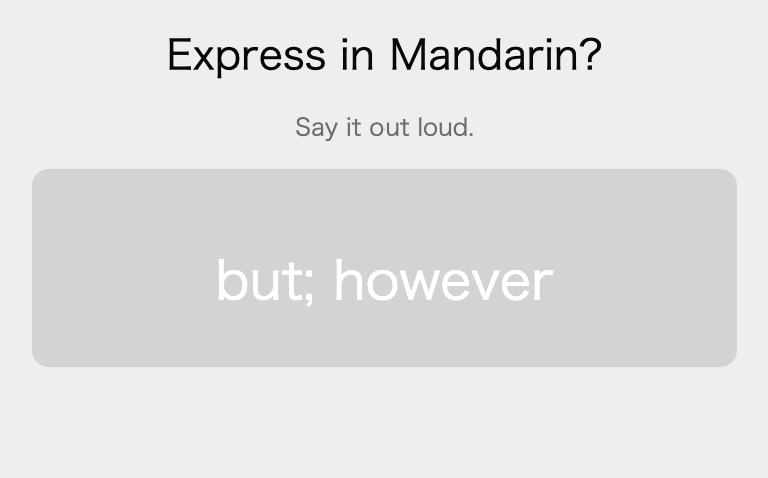
But there’s many ways to say “but” in Chinese. I have no idea of knowing which one this card is asking for.
The way I deal with this is simply accepting any synonymous answer as good. For example, this card was specifically 但是 (but):

If I had said 可是 (but), which is synonymous in most contexts, that would’ve been fine too. I’d press “Good”.
There’s a lot of nuance here: 可是 and 但是 might have slightly different contexts in which they’re used. Or these two both generally mean “shape”, but with subtle differences:


An analogous problem exists for sentence practice. For example this card and it’s “official” response:
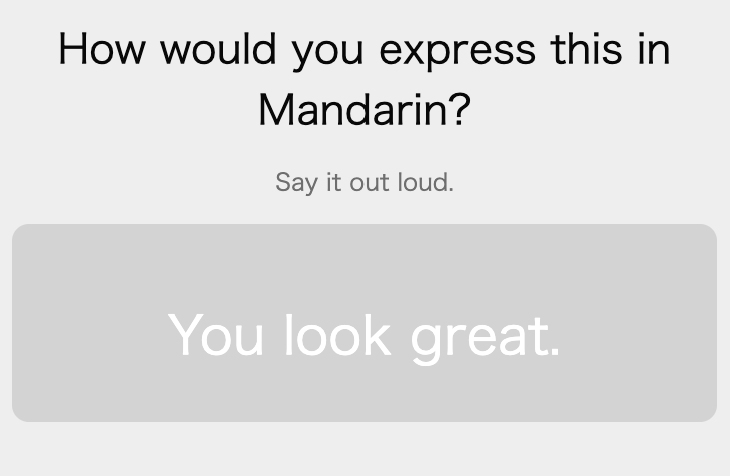
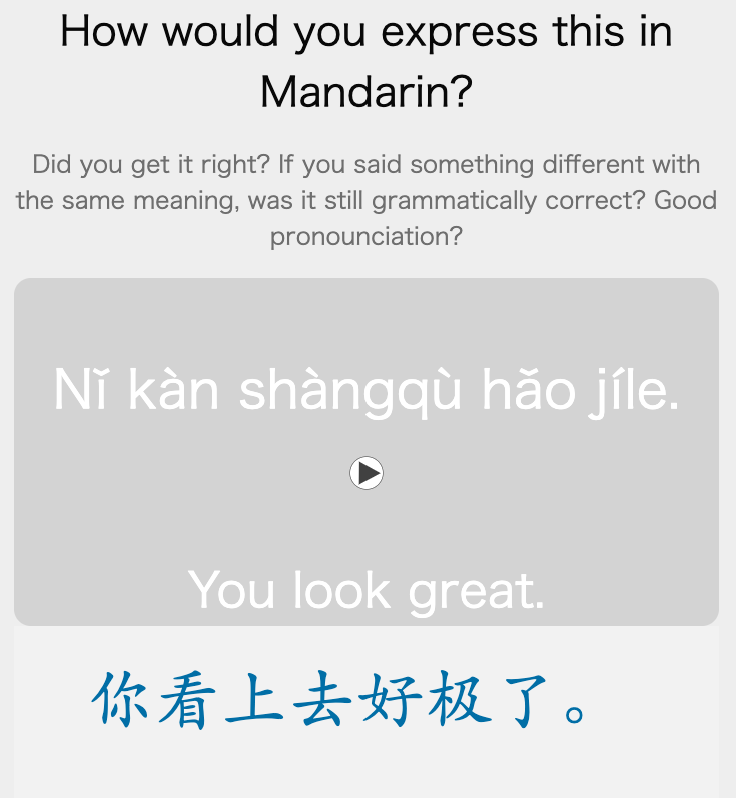
If I responded with something that to the best of my grammar and vocabulary knowledge was correct, then I’d still press “Good”. For example, responding with “你长得很好” would be perfectly fine here.
Doing this and allowing for these synonymous answers has the advantage of me finding ways to say it in a slightly new way every time I see the card. Of course, I have to be honest with myself, and also have an okay understanding of the grammar I used to judge whether it’s correct.
In general, I didn’t find a better solution to this, I just developed a certain intuition for what I’d honestly count as a “good enough synonymous answer” or where I felt I didn’t quite capture the correct word and had to press “Again”.
Decomposing characters into radicals
I found it useful to decompose new characters into radicals. As a simple example, when I learned 时 (time) first, I jotted “day inch” into my note field:

Referring to the left radical 日 related to “day” and the right radical 寸 meaning “inch”. It’s now easy to spin a little story around those radicals: “How a day inches along means time” or “A sun clock measures time in inches”. Sometimes these stories are true, and that’s the actual etymology. Here’s the link to a database of a legendary researcher who actually hunts down the etymologies of characters.
But languages are weird, and often there’s no proper origin story, or the character just swapped meaning some centuries ago. That doesn’t matter for learning. I found that once I decomposed a character like this and made-up a little story myself, the character would just stick. It’d be easier to write it, and easier to remember.
Later, it became substantially easier to decompose characters in my mind. It became a lot easier to just remember more characters correctly. It took less conscious effort. Now I take these kinds of notes on the card only if I get a character wrong multiple times.
Decomposing words into characters
Analogously to the above, decomposing a multi-character word into its component characters is often very useful. As a quick example, 巨人 consists of “giant” and “man”, clearly meaning “giant”. When studying a word first or getting it wrong a few times, I’d jot that decomposition down into the “Notes” field on the card, and move on. Decomposing words also often required me to actually look up the characters and figure out what they meant, which was key for learning lots of characters.

Interference of Similar Words
Often, it becomes really hard to differentiate characters. Especially once you learn similar characters, with similar radicals. Take these three, for example: 戴, 裁 and 载. I’d find just learning one of these very easy. But once I got to all three, it’d be hard to keep them apart. Especially without context. This effect is what Woźniak fitting calls interference.
A small trick I like to do: When reviewing cards, I like to just list out all the similar characters in the note field of a character which I confused. For example, I’d see 戴 (dai4, to wear) but mistook it for 载 (zai4, to carry, to load). Then I’d take a second to go into the anki card, and add add these similar characters into my note field that only shows up after I review a card:

Then, I’d carefully consider the radicals of the characters, and how they differ. The left hand radical in 戴 (to wear) resembles that in 机翼 (plane wing). Compare that to 裁 (to cut out) with its “clothes” radical 衣 on the left.
Usually I take note of this, ponder their composition carefully, and then see that analysis every time on the card’s back. This is often enough to resolve the interference between very similar characters and words.
Note that interference will make it easy to mess up reviews of cards, but I found it not as harmful in real life: Most characters show up within 2-character words embedded in the context of a sentence. Also, if you’re not just reading, there’s the sound of the word, and that serves as a reliable clue to the memory. That makes it substantially harder to confuse them. Anki is an extremely useful tool, but Anki isn’t the real world.
Differentiating terms
Chinese, as any language, is packed full of words which have similar meanings. It feels like there’s at least five ways to say anything. All with slightly nuanced meanings. I mean, consider just how many characters refer to “seeing” in some way: 看, 瞧, 望, 瞄, 观. Or ways of saying “say, talk”: 说, 讲, 谈, 聊, 讨论. This is frustrating at times. But I found it worth remembering that this isn’t unique to Chinese at all. For example, my native language, German: sagen, sprechen, reden, erzählen, diskutieren.
I found that the most important way to deal with this is to just consume and produce a lot more content. Immersion, immersion, inmersión, imersão.
That said, a trick I found useful was to also list all these adjacent terms in the note field of a difficult card:

This would take a few minutes every time. I’d start out freely associating words that come to mind. Then, I’d search in my Anki and online for more related words I didn’t know yet. It’s a great way of reminding myself what different ways exist to express a concept and learning a few more.
Usually, I found it most useful to infuse this with some semantic structure. For example, not only listing all the synonymous-ish terms, but also all related terms that come to mind. Like here, listing, all words describing time duration, increasing with every line break:

Once this was done within one card, I’d usually copy this semantic structure to the notes field of most terms which were listed. This meant I’d see it quite often, which was helpful.
Semantic batching
Almost every day, I’d study a few new characters just based on their frequency. This means I didn’t have any context or word to draw from.
So whenever I’d study a new character, I’d search for it in my Anki, and then choose some high-frequency words and phrases that use the character. I’d unsuspend those.
Often, I’d then jot down the unsuspended and related words in the “Uses” field of the character, reminding me of the context. This meant, within the same day or two, the new character would be firmly positioned within a little bit of context and its common uses.

In my opinion, this was crucial when studying characters in isolation. Searching for the characters in my anki would lead to quite surprising insights. Often, the denoted “official” meaning from the dictionary entrance was basically useless: It turns out the character is actually used completely differently. Or that the character is mostly used for transliterations, and it only has phonetic value.
Semantic contextualization
Context is key. Analogously to studying related words when studying new characters, I’d study new sentences when studying a new word.
Some words are easy and make perfect sense. Especially adjectives and nouns tend to be straightforward. Their use doesn’t vary wildly, and with a few examples you can generalize correctly.
But most words aren’t straightforward. They’re used in specific contexts. They have connotations. They require a specific sentence structure. They’re formal. They’re informal.
So whenever I encountered a difficult word, I searched it in my anki. Then, I’d pick a few sentences which I’d understand easily (i.e. they used mostly known words and grammar apart from the new word). I’d unsuspend those, and study them within the same session or at most within a few days.
Combined with the previous method, this meant I’d almost never learn something in isolation. Characters would always quickly be positioned in the context of words and sentences, and words in the context of sentences.
Every time I’d learn a new character, I’d learn 2-4 new words. Often the new words also had new characters, which I’d also unsuspend, study, and learn 2-4 new words with. For new words, I’d often unsuspend a few sentences, which gave me practice of both the characters and the words. Then, the sentences would often contain new words and characters too…
For example, I’d see 愿 (to hope, to wish). This would lead to me unsuspending and learning 愿意 (be willing to), 不愿 (unwilling), 自愿 (to volunteer), 愿望 (desire, wish), 祝愿 (to wish) and 如愿以偿 (to have one’s wish fulfilled). If any of those new words was hard to remember, I’d unsuspend and learn 2-3 sentences each, for example 那要看他愿不愿意 (That depends on whether he’s willing). If I hadn’t known it, I’d now also go and study the 那要看 structure. Repeat.
Sometimes, a single new character could lead to 5-15 new other characters and words, all embedded in some context. This batching combined with contextualization was powerful. It goes without saying that it accelerated my studies a lot.
Adding synonyms and notes to note field
One quick thing I like to do when studying a word: Quickly jot down all the synonyms, antonyms (opposites) or related terms in a note field. It’s a good exercise, and allows me to make important connections between words.

Vocabulary support mid-conversation
One thing which never went away so far is the need to ask Chinese speakers to explain some of the vocabulary they use. As any language, Chinese is just vast and people will use words I don’t know. Sometimes, those are clear from context. But often, I need to ask. This contributes to the feeling of “always a beginner”. It’s frustrating. I’ll have to ask many times, forever. But that’s okay.

Posted by the one and only u/[deleted]
Advanced
Some methods, thoughts, and tips which were helpful to me going from intermediate to advanced. As usual, use the sidebar to navigate.
Chinese Text Analyser
Chinese Text Analyser (CTA) is an extremely useful segmentation algorithm developed by Imral (launch post, reddit, website). It makes it easy to assess the difficulty of any content for your personal level of understanding, like this reddit user did for some content.
You can export your known vocabulary from e.g. Anki and then feed it into CTA. Then, you can also feed CTA some content you want to consume: Books, subtitles of a series, etc. CTA will tell you the breakdown of how much of the content you know, its HSK levels, etc.
CTA has flaws, for example in how it segments Chinese content. Nevertheless, it was so good that I didn’t even find the time to try alternatives. It quickly became one of the most powerful tools for me in the second half of the year, as described in this section.
Expanding Vocabulary
A few months in, I found my Anki often didn’t contain vocabulary I looked up. The words were too rare, and it wasn’t part of any of the premade HSK-based decks I had used as the foundation for my Anki. When encountering new words not in my existing decks, I could now painstakingly add every new word to my Anki, eventually thousands and thousands of cards. Usually, making your own cards is great for studying and serves as a key step for checking whether you actually understood what you studied. But for language learning, I think premade cards are an important timesaver, and the actual focus of my studies should be on 1) reviewing and 2) immersion.
So instead, I found the subtitles of shows I was watching, or converted books I was reading to txt. Then, I passed that text into the Chinese Text Analyser to parse it into words and characters. Here, I’d ignore the frequency-sorting aspect of CTA. Instead, I’d directly export all vocabulary from CTA as a CSV file. I’d import this CSV into my Anki.
Then, using regex filtering like ``` Hanzi:re:^.{1}$ ``` to search for all single characters, I’d go and split the imported vocabulary into characters versus words, and assign them to the correct note types. Then, I’d add AI-generated audios to all cards.
After some further cleaning up, my Anki had vastly expanded. Now, my Anki contained almost all the vocabulary I’d ever encounter in the content I liked.
With the power laws governing language frequency, this meant that I’d have tens of thousands of words which only showed up a few rare times in my entire corpus of content. Often words nobody would ever actually use. There’s an enormous long tail of cards with a frequency of “0.0001” in my Anki. Roughly 11,000 of 60,000 words and characters show up as 0.0001%, or once every million words.
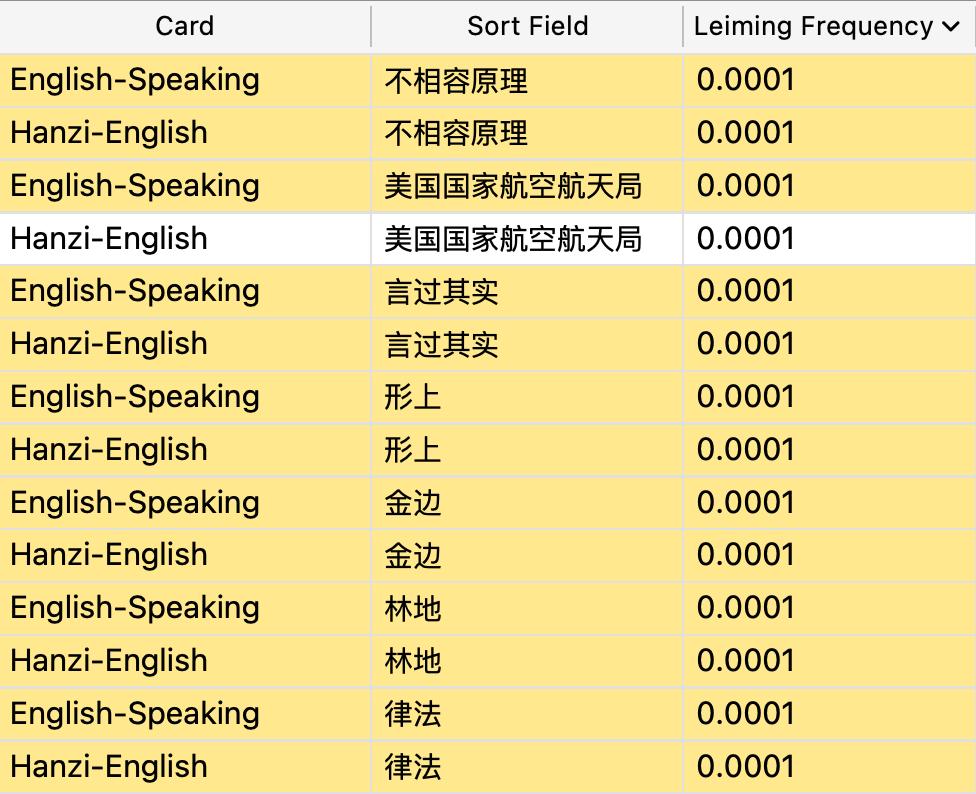
Ah yes, the Chinese term for NASA, very crucial
This has obvious disadvantages: My deck is huge. It’s a dictionary. It’s a database. Searches for simple characters can easily return dozens of results, many of which are rare words I need to ignore.
But for me, I have enough experience in Anki-jitsu that I can deal with those disadvantages. The expansion was very worth it on the net: I have almost every conceivable vocabulary ready at-hand, not just up to HSK6. Rare Chengyus, rare vocabulary, technical vocabulary. The screenshot above has the word for “NASA” — I do want to know that! (It came up in the Three-Body Problem or so.)
I can now use Anki as my main dictionary and smoothly study directly from it, instead of having to use multiple apps and spend hours adding my own cards.
Study HSK, then ignore HSK
It’s hard to objectively measure progress in language learning. The most common way Chinese language progress is assessed is the HSK system (compare to the European CEFRDS[] A1 - C2 system). At the beginning, HSK is great. Think about HSK as a collection of the most common words in Chinese (and key grammar, etc…), across all contexts and materials. HSK1-3 are simply important to everyone. In the beginning, I found it helpful to study mostly those words.
But you will not encounter words at their frequency across all contexts. Beyond the basic HSK levels, the tested vocabulary diverged so radically from what’s most useful to me — especially as my niche interests developed.
For example, HSK5 and HSK6 are heavy with business-related vocabulary — useless to me if I’m mainly watching sci fi shows and anime dubs of ninjas! Eventually, to achieve that true Fluent™ I’d need to know it all. But I’m still learning. I need to prioritize.
What use do I have for knowing how to say “reimbursement” and “lay-offs” if I am mostly interested in, say, Avatar — The Last Airbender? Watching the Chinese dub, I was very busy trying to understand “waterbending” and “everything changed when the fire nation attacked”.
Make your own HSK
I know some 8,000 words and characters, and HSK6 requires 5,000, but I wouldn’t pass an HSK6 exam. Why is that? Instead, taking this idea of the irrelevance of advanced HSK much farther, I made my own HSK: a customized frequency index.
Say, you took an enormous corpus of a language’s internet text, books, media, subtitles, parse it, and sort the list of words in the material by how often they relatively show up. You’d notice that this frequency list is extremely powerlawed. For example, 的 makes up some 5% of the all words, but 忍者 (ninja) only 0.05%. This leads to statements like in the form of “the most common 1000 words in a language account for 80% of all used words”. Note how languages often have tens of thousands of words! Of course, you’d want to radically focus on the top 1000 first, rather than a random sample from the entire 50,000 words in existence. HSK is roughly frequency-based. Most language courses are roughly frequency-based.
Some five months in, after an initial vocabulary of 3,000 words (think HSK4-5 level), I made a list of content I’m consuming, interested in consuming, and things I generally love. Then, I tracked down the subtitle files, epubs, and PDFs online. I appended all the words being said in your favorite content into a single ginormous text file, which I’d pass through CTA and then import into my Anki. Here’s a more detailed outline of the methods:
How to find subtitle files
I use the Chinese subtitle files from movies, anime, and TV series—especially content I’m really invested in or interested in. Here are some websites to find these subtitle files:
Creating Super Text Files
These are merged files that I create from various Chinese books and subtitles, giving me a rich source of new words to study. Here’s my process for putting one together:
- Download Chinese subtitle files in any format (SRT, ASS, etc.) or find books in Mandarin to use as source material.
- Convert the subtitle files to plain text. I usually use online tools like GoTranscript for this, while Calibre (a downloadable tool) is great for converting books. Once converted, save all these files in a single folder.
- To combine all these text files, open the Command Prompt directly in the folder where they’re saved. You can do this easily by navigating to the folder in File Explorer, then typing cmd in the address bar and pressing Enter.

- Once the Command Prompt is opened, type the following command to merge the files:
This will combine all the text files into one super text file.
I passed this file into Chinese Text Analyser, which returns a full ranking of what words and characters are most commonly used across all content. You can export this as a (ginormous) table of word / pinyin / English definitions / frequency and import it into Anki. I import it by first making it a spreadsheet, then exporting that to csv, then importing that csv to Anki.
Then, there’s usually some magic and sometimes some wrangling with the Merge add-on to fuse that new frequency list into my existing Anki cards. A very rough outline of steps looks like:
- A: Deleting the previous frequency field
- Go to the character and word note types, and delete my custom frequency field
- Add a new field with the exact same name
- B: There’s an alternative way to deleting the previous frequency field
- Clone the two note types for characters and words
- In the cloned note types, delete the existing frequency fields
- Convert all character and all word cards to that new cloned note type, transferring all fields except the missing frequency field which is then dropped
- Convert them back to the original character / word note type. The frequency field is now empty
- Import the vocabulary CSV file from Chinese Text Analyser
- Choose the option to not update existing cards
- Find a way to merge the new vocabulary cards with the existing cards
- Back-up your Anki collection
- You want to merge the new exported cards from CTA into the existing cards, so you don’t lose your study progress and other fields you might have
- Getting the direction right usually takes a bit of experimentation with the settings of the Merge add-on
- Use the “Find Duplicates” function in the browser, and co-locate the correct decks where you previous cards and newly important cards from CTA are
- Merge duplicates
- See if you lost any cards and any information on cards. Did it merge in the right direction? Was the direction correct for all cards? Did you lose any information or cards?
- If you’re fast enough checking this, you can CMD+Z undo the Merge. Otherwise you’ll have to roll back to your backup.
- Try different Merge settings and try again.
This becomes easier after some practice. If enough people are interested in this, I can add more detail on how this process usually ends up looking for my set-up.
After this successful anki-wrangling, I have a custom priority ranking of the vocabulary. This ranking was based on in content I would like to consume.
I’d unsuspend the most common words in batches and study them, like one would study for HSK. But instead of HSK, the vocabulary I studied were the things that actually came up the most in my personal niche interests and content I liked.
This accelerated my studies tremendously. I was able to reach “fluency” in the context of my personal content much faster, and then I was able to use this strong basis for novel content much more easily.
Expanding Vocabulary
It's time to use these super textfiles to expand my vocabulary on Anki:
- Open Chinese Text Analyzer. If your known words are not already in CTA, import them using the 'Import' option from the File menu and import the text file of your known words.
- Load the Super Text File.
- Click on the File tab.
- Select Open and choose the super text file you created.
- Export Unknown Words.
- Click on the File tab again.
- Choose Export.
- Select Export To File (you can also choose email or clipboard if preferred).
- In the export options pop-up, make sure only unknown words are selected.
- Add any fields you want to include and click OK to export.
- Import into Anki.
- Open Anki and go to File > Import.
- Select the file you exported.
- Choose the correct field separator.
- Select the note type and deck for the import.
- In the Existing Notes section, select Preserve to avoid duplicates.
- Optionally, tag all notes for easier grouping.
- Match the field mapping based on your data.
- Click Import to complete the process.
- After importing, Anki will show details on the number of new notes created and preserved.
Weighted Personal Vocabulary
Recently, I’ve been experimenting with a modified way of building a personal corpus and frequency list.
For example, I might really like a certain anime or book (Three Body Problem!). I might read it over and over again. I’m exposed to that vocabulary much more often. But in my personal corpus, that’s not reflected. So, as an obvious solution, I’ve been trying weighted personal vocabularies:
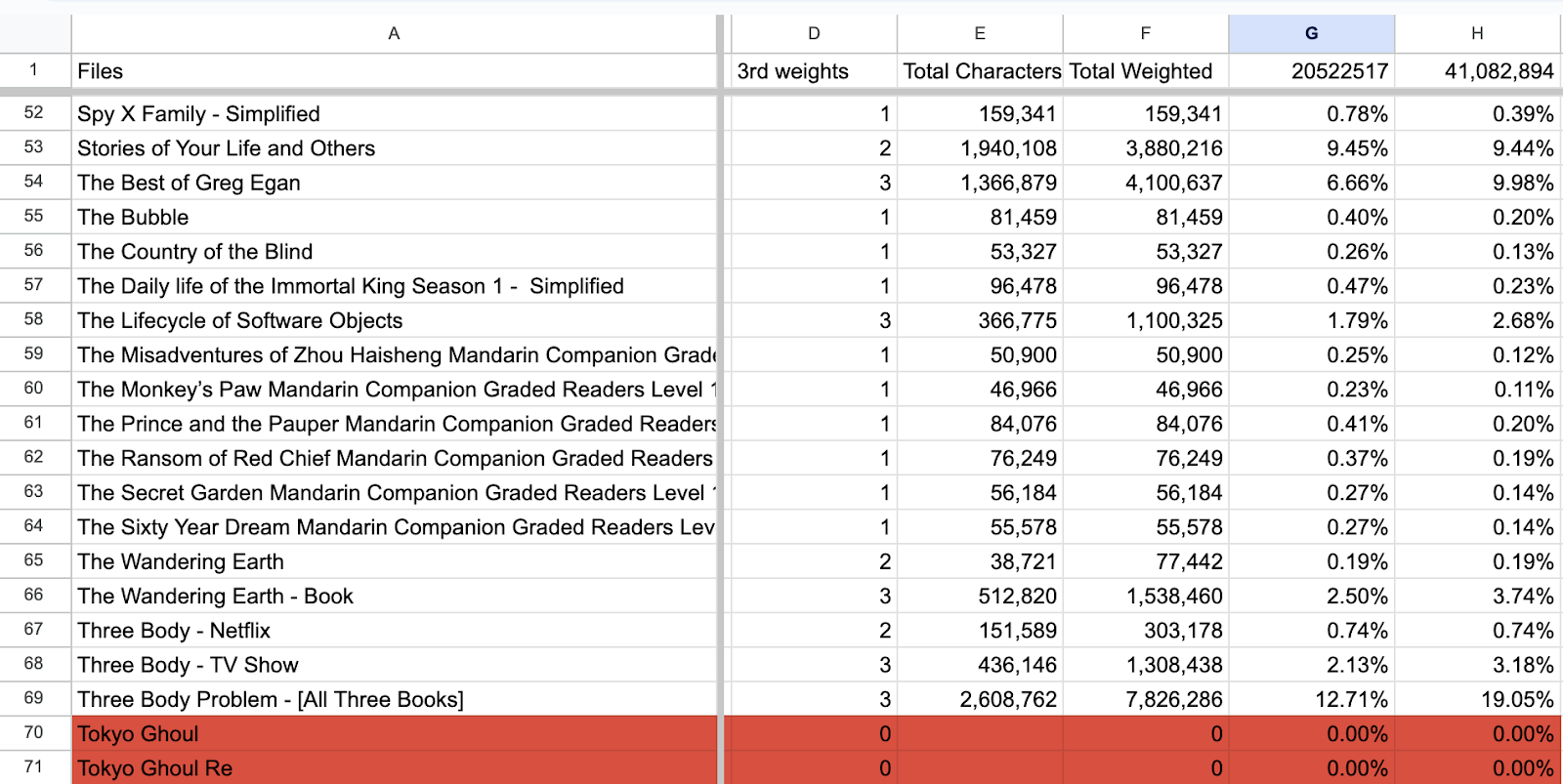
Content / Weights / Total characters (unweighted) / Total characters (weighted) / Percent of the sum of the corpus (unweighted) / Percent of the sum of the corpus (weighted)
Weighing some piece of content would then just mean more copies of that file in my personal corpus.
It’s a bit early to say, but my impression is that this will direct my studies more effectively towards the content I care about and content I find exciting. Then, I’ll be able to read that more fluently, which in turn accelerates my language learning pace. Reading content I care about at higher comprehension percentages will allows me to learn more new vocabulary faster and consume more content, which in turn generalizes to better language capabilities inside nad outside of my personal corpus.
Personalized immersion for the win.
Updating Frequency
If you’ve successfully wrangled some of the previous steps, and you create a new corpus, here’s a rough outline how to update the frequency of vocabulary in your anki based on a new corpus. I did this roughly once a month at peak.
Note: These steps assume that you have already completed vocabulary expansion and that all words from your custom text file have been added to Anki.
- Prepare Anki.
- Open Anki and ensure it is synced.
- Create a Backup of your Anki deck to safeguard against any potential issues.
- Export your Deck as an additional precaution (you can skip including media if it takes too long).
- Export Your Personal Vocabulary.
- Open the Anki Browser by clicking 'Browse' in Anki. Use the search bar to filter for your personal vocabulary notes.
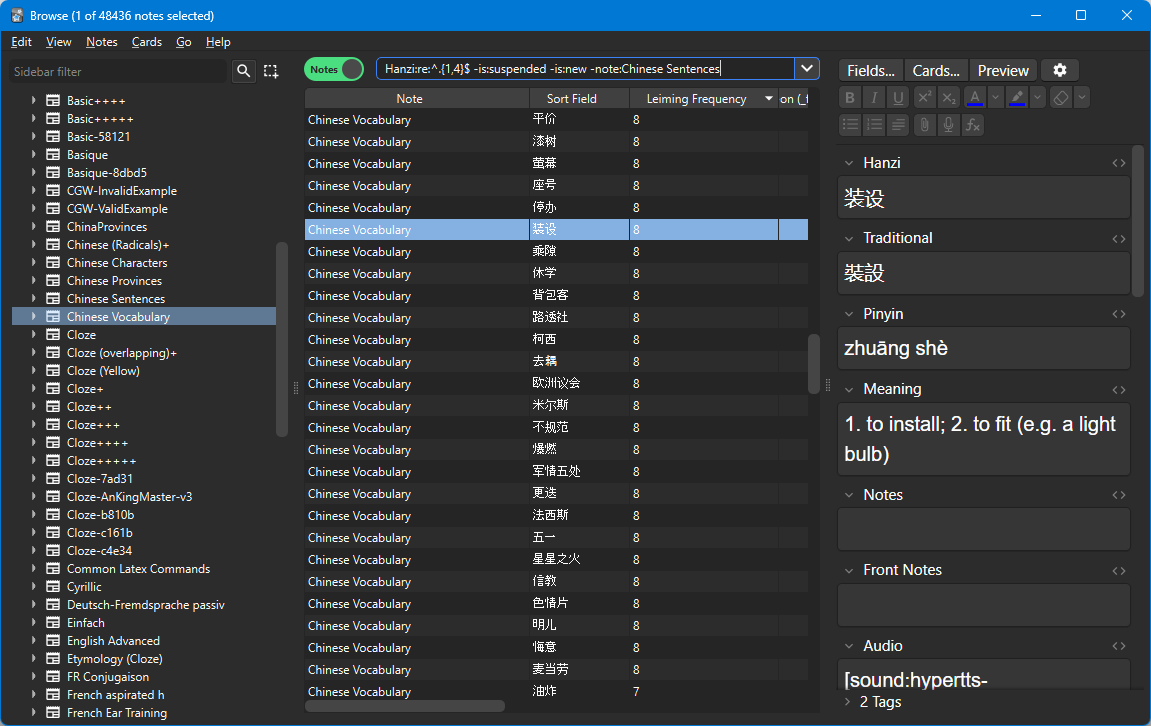
- Here’s a sample filter: Hanzi:re:^.{1,4}$ -is:suspended -is:new -note:Chinese Sentences"
- This will find notes with one to four characters that are not suspended, not new, and not part of the 'Chinese Sentences' note type.
- Switch to Notes Mode in the Anki browser.
- Export your Vocabulary:
- Select your notes, and export them as plain text.
- Ensure no references or tags are included in the export by unchecking these options in the export dialog.
- Prepare the Chinese Text Analyzer (CTA).
- Open Chinese Text Analyzer (CTA).
- Import your Personal Vocabulary into CTA.
- Analyze and Export the Frequency Data.
- Open your custom text file which contains all of the words that you currently know.
- Export the Frequency Data. Choose to export all words, keeping only the frequency and the word itself.
- Import into Anki.
- Open Anki and ensure your backup is ready.
- Create a Temporary Deck in Anki to import the frequency data.
- Import the Frequency Data:
- Import the data as a Chinese Vocabulary Note.
- In the Existing Notes section, select Update to avoid duplicates.
- Tag the cards for better visibility and grouping.
- Map the frequency field in the imported file to your custom frequency field in Anki. Make sure to map the word to the Hanzi field and the frequency to the Leiming Frequency field when importing.
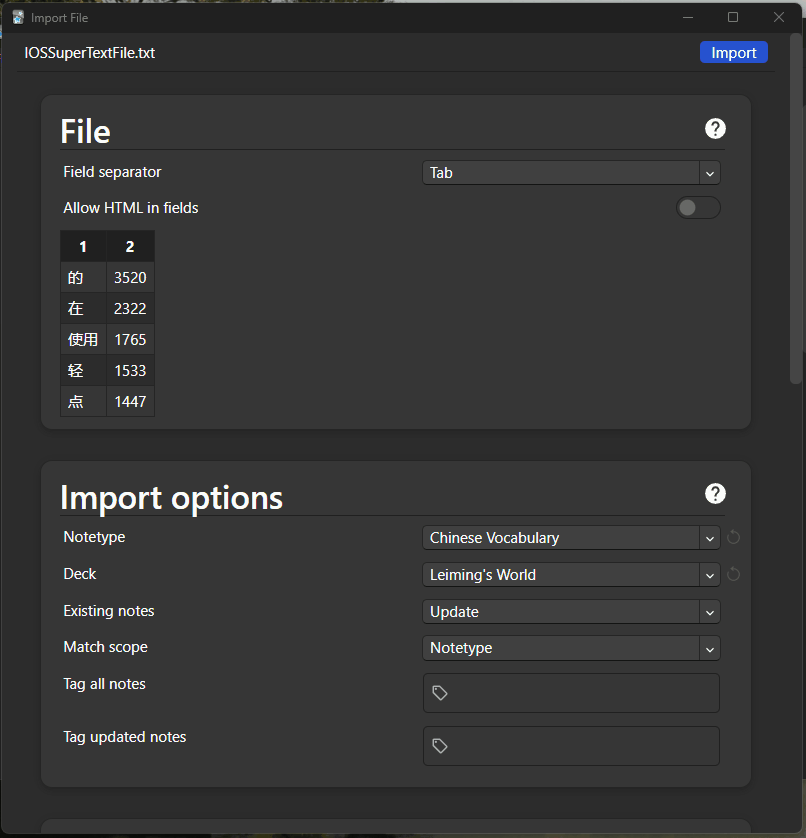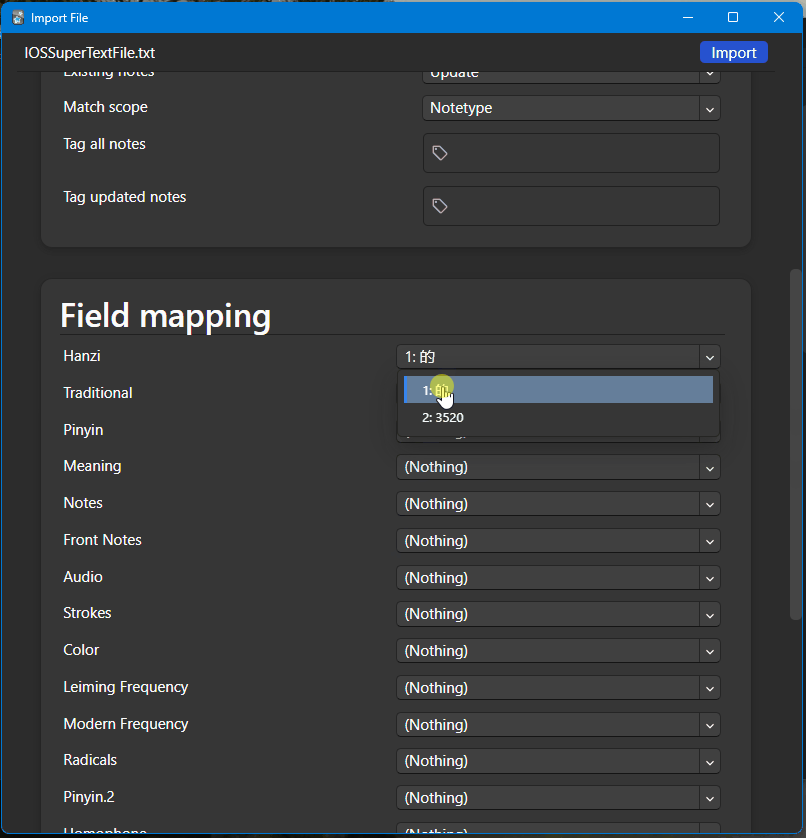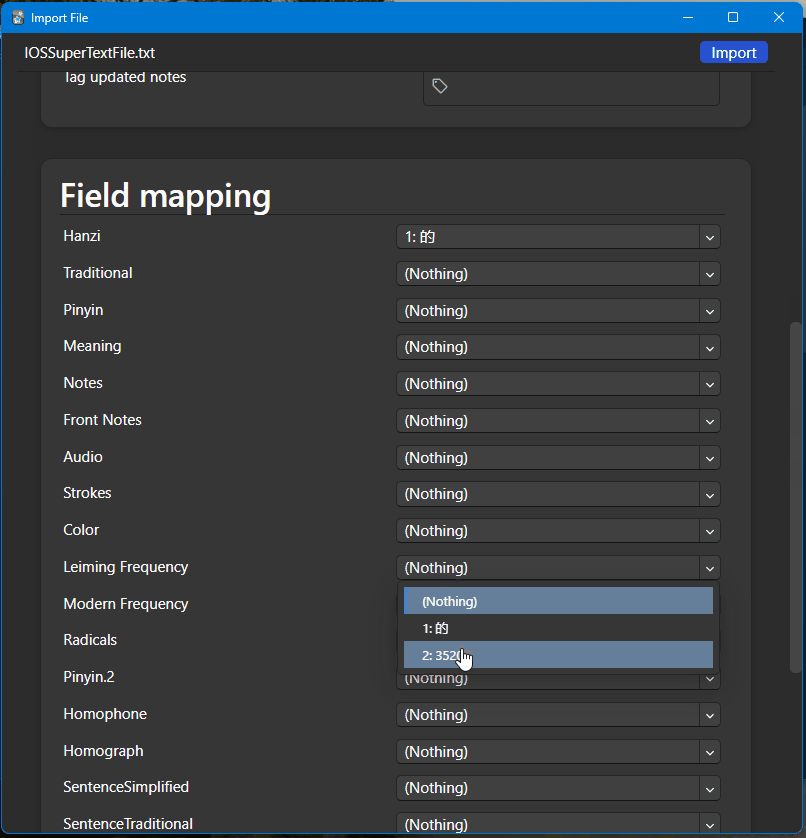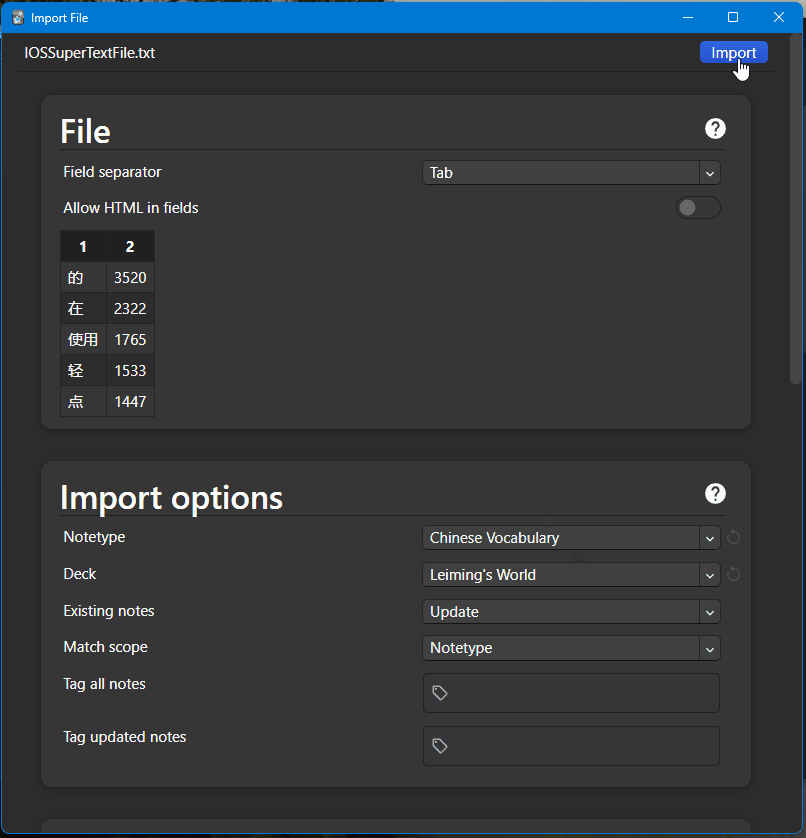
- Ensure that the frequencies of the words in Anki have been updated correctly.
- Import again as a Chinese Character note.
- Repeat the Import Process for single characters, ensuring they are updated with the correct frequency.
- Final Verification:
- Ensure all frequencies are correct and that no data has been lost or incorrectly mapped.
- Backup and Finalize:
- Create a Final Backup of your Anki deck after ensuring everything is correctly updated by going to 'File' > 'Create Backup’
Removing Long Sentences
When you choose to include the “Line” option when expanding your vocabulary based with CTA, it’ll export a sentence from your custom corpus where that vocab shows up. Especially if that sentence is from a novel, it might be way too long. If you think the sample sentences are too long for the cards, here’s what you can do to remove them.
- Launch Anki, create a backup, and click on Browse to open the Browse window.
- In the Browse window, click on Notes in the upper left.
- Select Manage Note Types.
- When the Manage Note Types window pops up, click Add and choose Clone to duplicate the note type used by the notes you want to clean up.
Duplicate the Note Type.
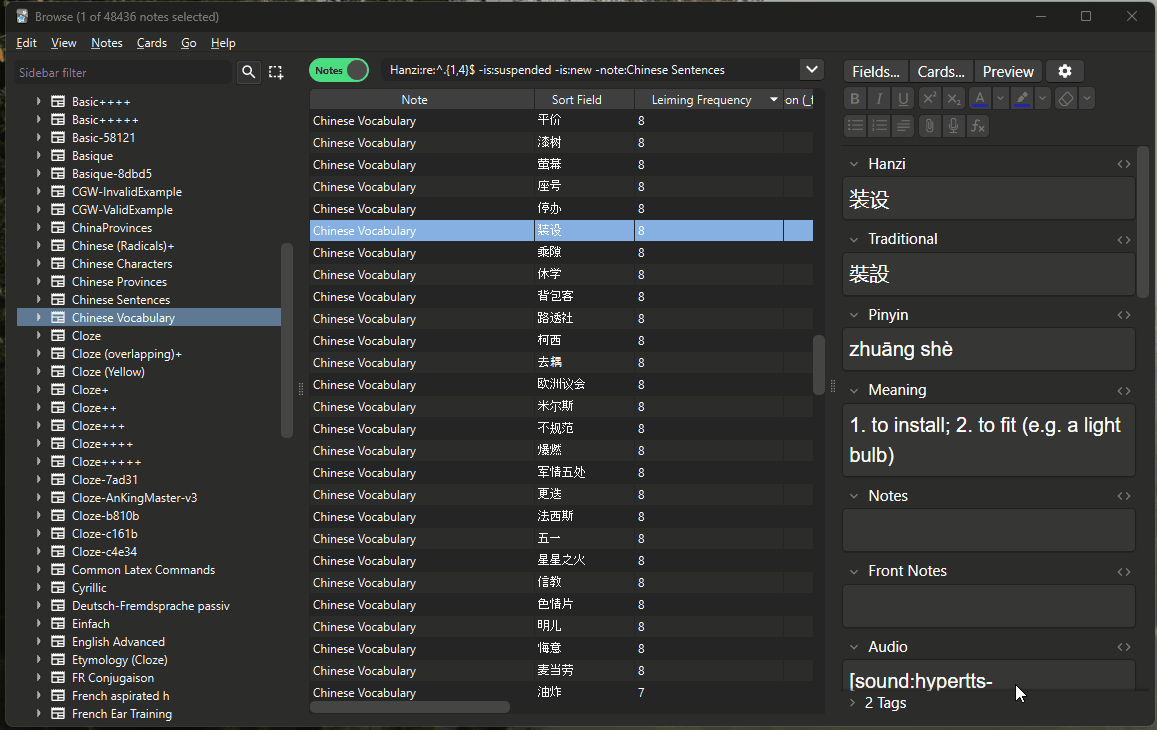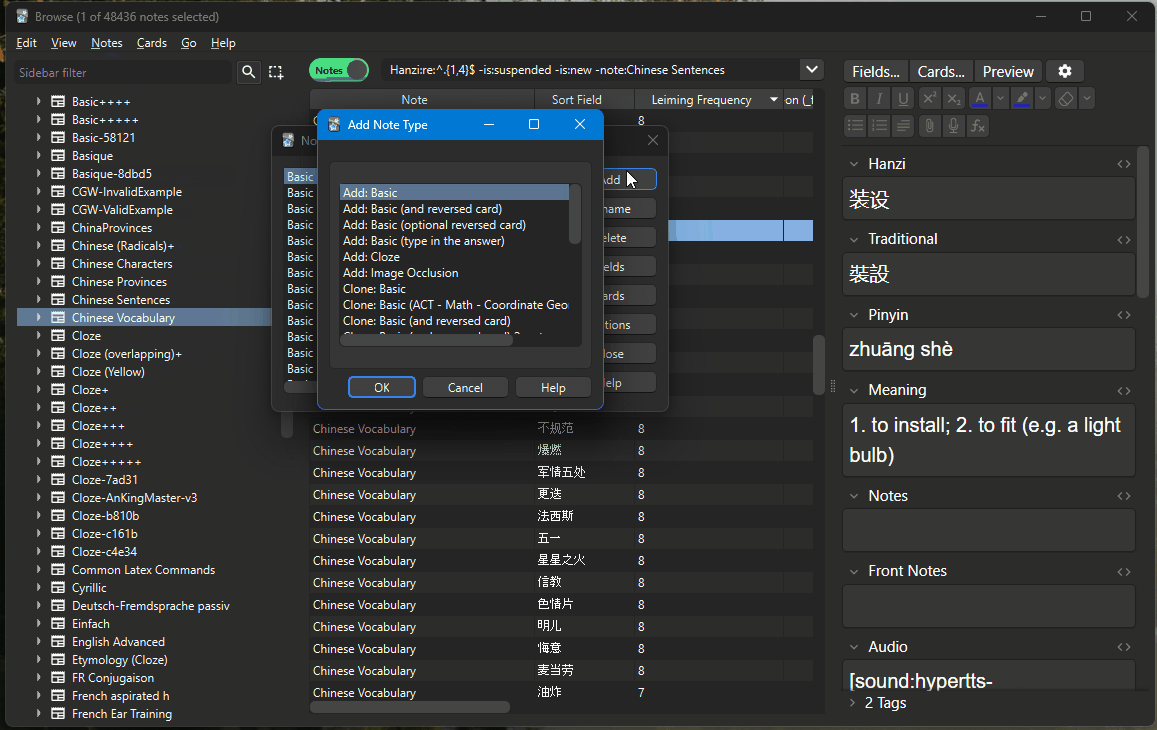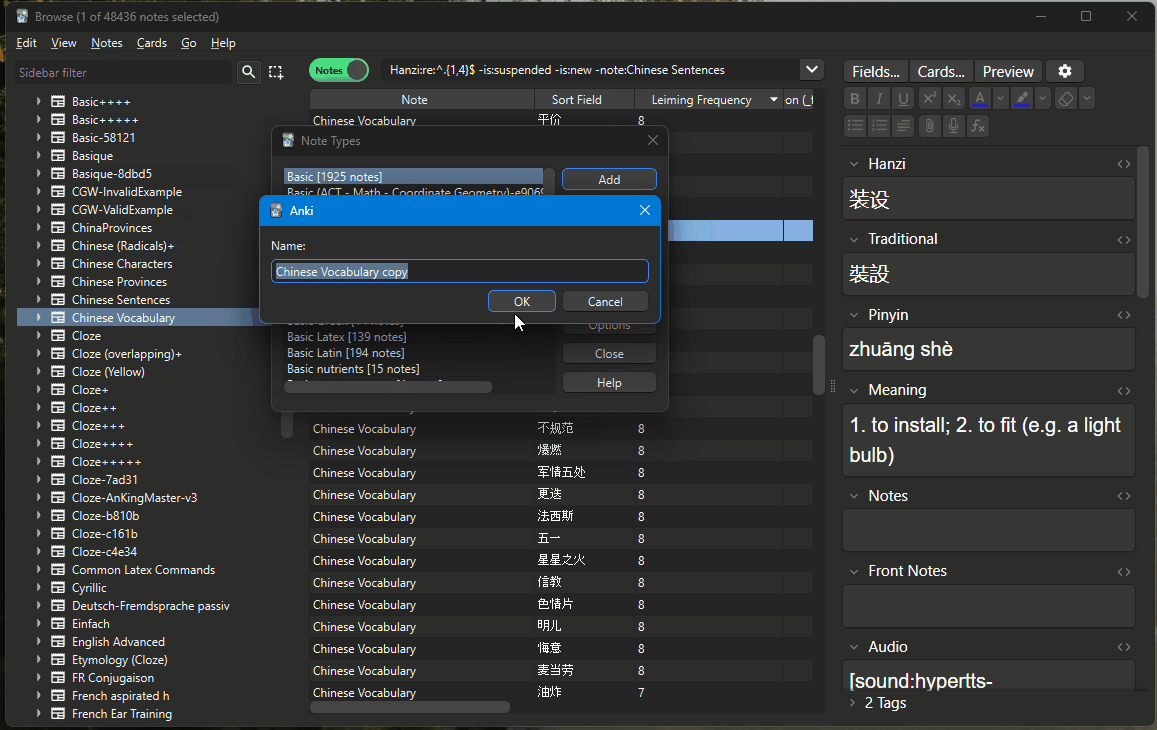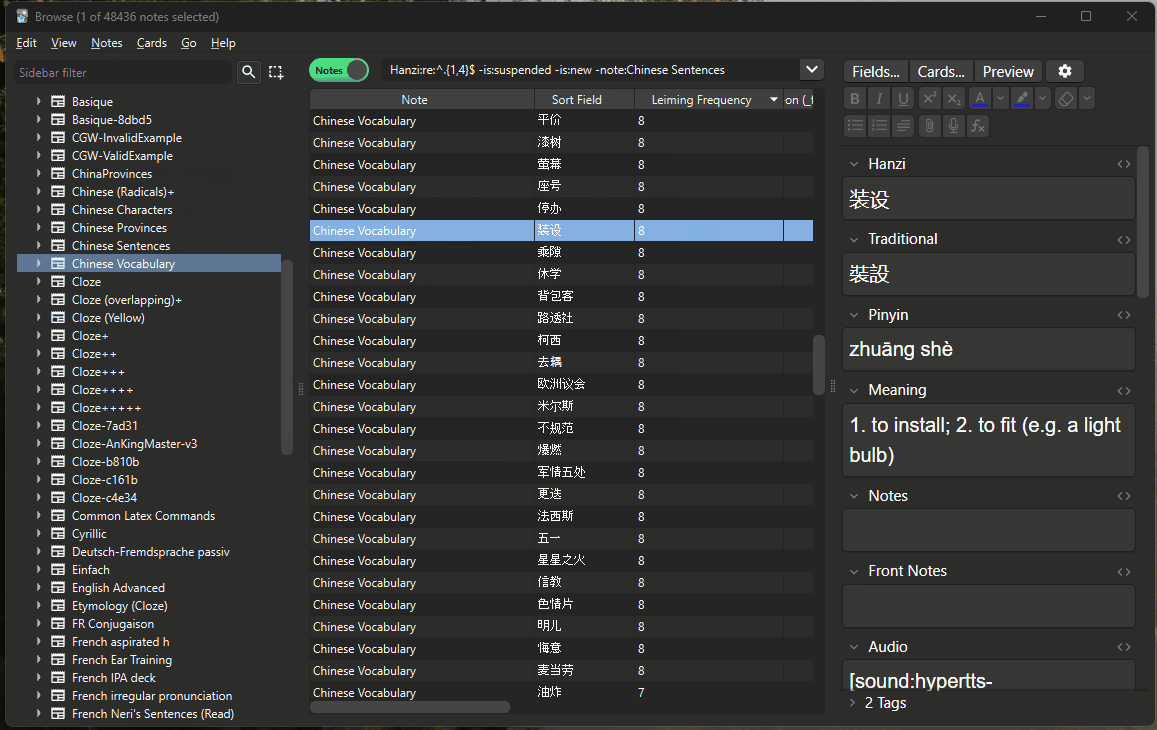
- Filter Notes with Long Sentences.
- Return to the Browse window and make sure you’re viewing the notes (not cards).
- In the search bar, enter the filter to find notes with long sentences in the SentenceSimplified field: SentenceSimplified:re:^.{35,}$
- This filter will find all notes where the SentenceSimplified field has more than 35 characters. Adjust the number as needed.
- Change the Note Type.
- Review the filtered notes to confirm they’re the ones you want to update.
- Select all the relevant notes, right-click, and choose Change Note Type.
- Change the note type to the duplicated one you created.
- Remove and Re-add the Field.
- In the Browse window, find the note type in the left-side panel.
- On the right side of the window, click on Fields to edit the note type.
- Locate and remove the SentenceSimplified field.
- After removing it, add the field back with the same name and in the same order.
- The long sentences should now be removed.
- Use Change Note Type again to switch the notes back to the original note type. After this, you can delete the now empty cloned note type.
Non-Comprehensible Input
At some point, I ran out of Graded Readers which I found interesting. I mean, I'm not exactly excited about fairy tales and folktales. So I started reading novels which were very hard for me: Instead of 95%+ comprehension, I’d sometimes only be at 70% comprehension.
This goes against the common wisdom in the language learning communities. But I realized that I don’t want to, I don’t need to read at 95% comprehension. It’s okay to just read way harder material! Of course, I’d have to read much slower and look up every fourth word. But if I really want to read something hard, that’s totally alright. Better to read something hard you’re interested in than not reading at all.
I’d start reading online wikipedia articles, random things I’d bump into, a Wechat article on penguin behavior: any content. Reading at less than optimal comprehension meant I’d need crutches and helpers. Reading in my browser, I’d use Inkah to look up things quickly by hovering over them, and I’d add the words to my anki if they came up often. Reading in Kindle, I’d use the dictionary function. Often I’d read a sentence or paragraph myself, try to guess its meaning and its component, but fall short of fully parsing it. Only after trying, I’d use the Kindle translate function (select the sentence -> translate), which often led to an “Aha” moment and 3-4 new words that clicked.
Now, after a year of Mandarin, most of Cixin Liu’s works are around 80% comprehension for me. I still don’t know multiple words per sentence.
But I love Cixin Liu. When I was 15, reading The Wandering Earth made me cry multiple times. I adore the Three-Body-Problem. It’s a pinnacle piece of science-fiction. I want to read it in Chinese, come hell or high water, come 80% comprehension or complex grammar.
Now, I’m carving my path through the Three-Body-Problem, chapter by chapter, sentence by sentence.
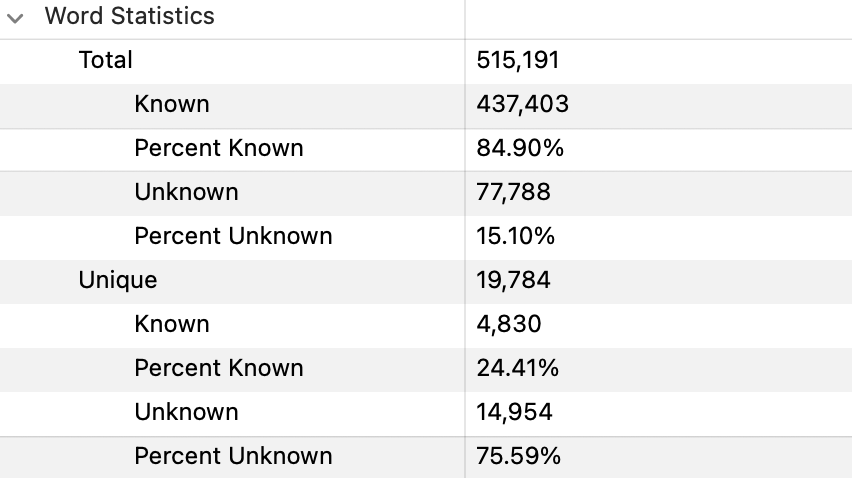
85% comprehension doesn’t sound too bad, except when the sentences are a page long and full of obscure grammar structures.
Quicklist of some watched content
This is a representative sample of roughly half the content I watched over the course of the year.
- Demon Slayer 鬼灭之刃 30h x2
- Scissor Seven 刺客伍六七 20h x3
- Boruto 20h
- TDLOTIMK 仙王日常生活 8h
- Naruto Shippuden last half (skipping fillers) 火影忍者 40h
- Bubble 泡泡 1.5h
- JJK 咒术回战 x2 20h
- Netflix Avatar 降世神通 8h
- Netflix One Piece 海贼王 6h
- Netflix 三体 x2 16h
- Attack on Titan 进击巨人 30h
- Spy x Family 8h
- My Hero Academia 我的英雄学院 25h
- Batman Trilogy 蝙蝠侠 4.5h
- Assassination Class 暗杀教室 4h
Practicing Chengyu on Spotify
One key piece of feedback I got recently was that I’m not using as many chengyus in my conversations as a native speaker would. My tutor mentioned that most native speaker might use a chengyu every 10 sentences, but I was using one maybe once every 50 sentences.
So what I did to study more chengyus and integrate them into my day-to-day life? I renamed all my spotify playlists to a fitting chengyu (or riffs on them). Native speakers would probably cringe.
But needless to say, after associating Hanz Zimmer with 波澜壮阔 and cozy moments spent listening to Lauv with 心平气和, I’m now using a lot more chengyu. Mission success! (自强不息)
From Translation To Fluency
Eventually, I started to try to associate most characters and words more with the concept than the translation. This is ongoing, and I hope to report back how this goes. I assume that more focus on the concept would allow for a more fluent expression, but who knows?
The dream of personal, gradual, full immersion
At the beginning, almost everyone is studying HSK1-3 or some slight variant of that. That’s great.
At that level, there are a lot of great graded readers, and with such limited vocabulary it’s hard to explore any niche interests of yours.
But as I got better, I didn’t want to read simplified fairy tales anymore. I wanted to read content in my fields of interest. I wanted to read scientific content, biology, neuroscience, biographies, history, and more.
With modern LLMs, it should be do-able to create books at your personal level of vocabulary. Just so that you understand 95%+ of the content easily. So far, there’s not been an app for this, but I’d happily pay for one. If I find the time, I might hack away at this myself.
The analogous idea would be awesome for online content: Imagine a browser add-on which translates any website, like Google Translate in Chrome does. But it does so catered to your level. As you learn more vocabulary, everything you read online adapts to that. New vocabulary is used in your everyday online content. Your vocabulary solidifies and expands.
The even more ambitious version of this: Imagine as you learn the language, based on exactly the words you know, your (digital) environment slowly changes more and more into your appropriate language level. At the beginning, any text you read on your phone, laptop, or e-reader has some vocabulary converted to the target language. It does so in a nuanced way; for example, it will only translate specific nouns, so it is clear from context, though it might sometimes be a bit awkward and not as natural as native speech. But that awkwardness in the beginning is totally okay.
As you get to a level where entire sentences are replaced, enabling large-language models to choose more natural ways to phrase the translated snippet. With the incredible abilities of modern LLMs, it’d be not too hard to get fairly okay-sounding sentences translated for the content you see, exactly titered to your language level.
There are early simple attempts, such as Toucan, which will replace some words to your target language on any website rendered. There’s u/fullfademan’s audio story generator based on HSK-level.
But a more comprehensive app, which slowly does so across more platforms, is both hard to build and still lacking.
I’d pay a lot for such an app.